因为我这种写法只有一个值
上面那个循环就是循环全部的p标签
那我就不知道了,我都是这么爬的
mainbodys = html.xpath("//div[@class='entry-content']") for div in mainbodys : p= div.xpath("./p/text()") 你这样试一下
看一下你代码呢
内容缺失?没爬取完?还是怎么的
你会正则的法你可以直接用正则简单些,不会的话你可以用这种麻烦一点的办法,选中你要获取内容的标签右击选择copy xpath
37,742
社区成员
34,213
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

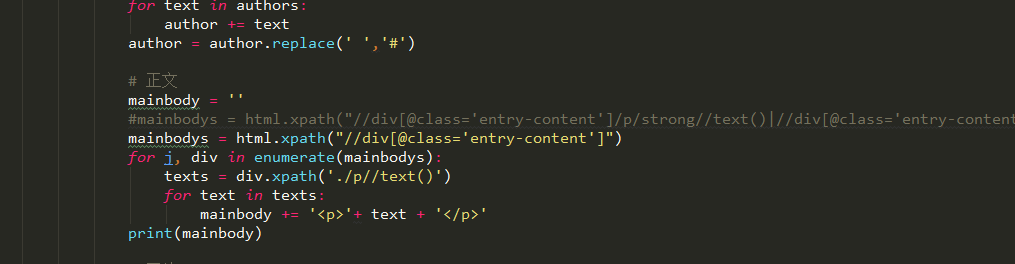
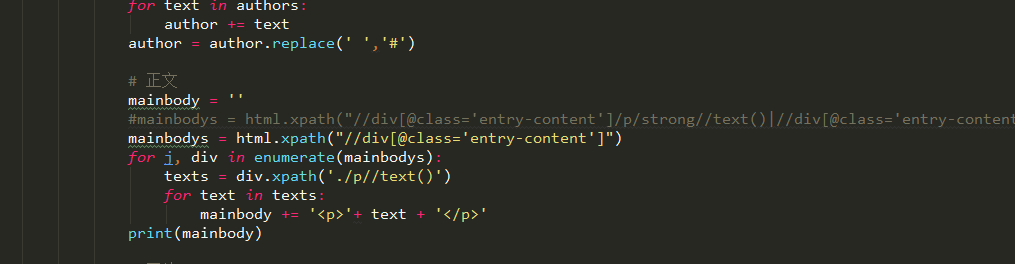 试了不行
试了不行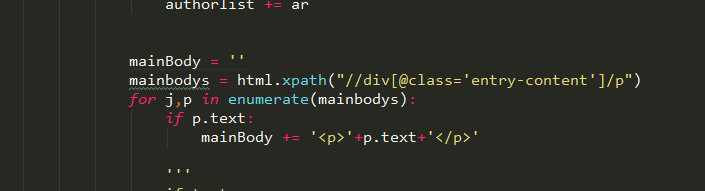 这就是获取p标签下文本内容的代码
这就是获取p标签下文本内容的代码




