社区
Informatica
帖子详情
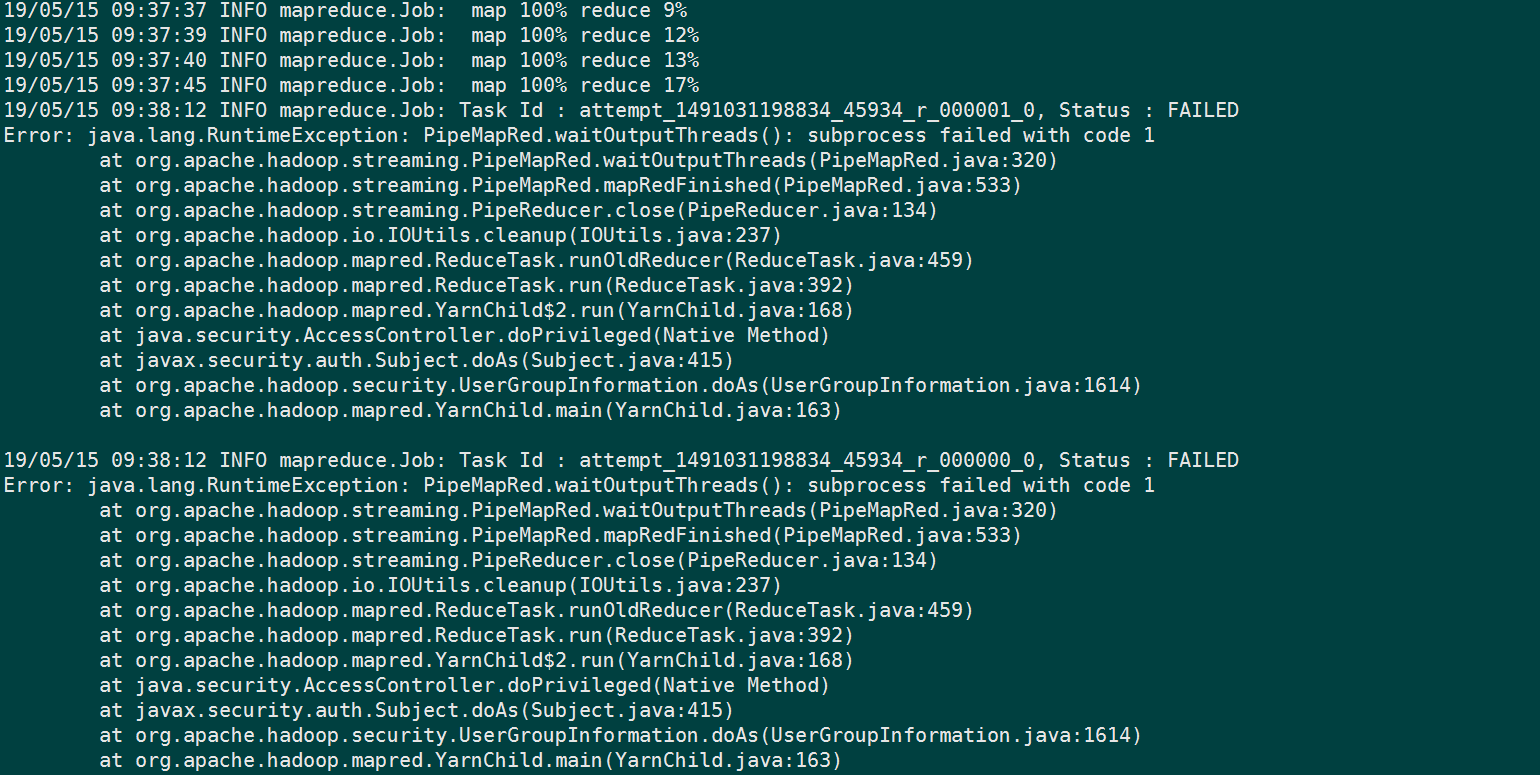
新手的问答——在hadoop集群上运行mapreduce时rreduce部分运行到一半就出错是什么原因呢?
remenber_smlie
2019-05-15 09:51:27
...全文
29
回复
打赏
收藏
新手的问答——在hadoop集群上运行mapreduce时rreduce部分运行到一半就出错是什么原因呢?
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Hadoop
权威指南 中文版
本书从
hadoop
的缘起开始,由浅入深,结合理论和实践,全方位地介绍hado叩这一高性能处理海量数据集的理想工具。全书共14章,3个附录,涉及的主题包括:haddoop简介:
mapred
uce
简介:
hadoop
分布式文件系统;
hadoop
的i/o、
mapred
uce
应用程序开发;
mapred
uce
的工作机制:
mapred
uce
的类型和格式;
mapred
uce
的特性:如何安装
hadoop
集群
,如何管理
hadoop
;pig简介:hbase简介:zookeeper简介,最后还提供了丰富的案例分析。 本书是
hadoop
权威参考,程序员可从中探索如何分析海量数据集,管理员可以从中了解如何安装与
运行
hadoop
集群
。 什么是谷歌帝国的基石?
mapred
uce
算法是也!apache
hadoop
架构作为
mapred
uce
算法的一种开源应用,是应对海量数据的理想工具。项目负责人tomwhite透过本书详细阐述了如何使用
hadoop
构建可靠、可伸缩的分布式系统,程序员可从中探索如何分析海量数据集,管理员可以从中了解如何安装和
运行
hadoop
集群
。 本书结合丰富的案例来展示如何用
hadoop
解决特殊问题,它将帮助您: ·使用
hadoop
分布式文件系统(hdfs)来存储海量数据集, 通过
mapred
uce
对这些数据集
运行
分布式计算 ·熟悉
hadoop
的数据和ilo构件,用于压缩、数据集成、序列化和持久处理 ·洞悉编~
mapred
uce
实际应用
时
的常见陷阱和高级特性 ·设计、构建和管理一个专用的
hadoop
集群
或在云上
运行
hadoop
·使用高级查询语言pig来处理大规模数据 ·利用
hadoop
数据库hbase来保存和处理结构化/半结构化数据 ·学会使用zookeeper来构建分布式系统 如果您拥有海量数据,无论是gb级还是pb级,
hadoop
都将是您的完美解决方案。
Hadoop
源码分析 完整版 共55章
caibinbupt的
Hadoop
源码分析完整版,包括 HDFS 和
MapRed
uce
。 HDFS: 41章
MapRed
uce
: 14章
大数据与云计算——部署
Hadoop
集群
并
运行
MapRed
uce
集群
案例(超级详细!)
这篇博客文章详细介绍了如何部署
Hadoop
集群
并
运行
MapRed
uce
任务。首先,我们将详细解释
Hadoop
和
MapRed
uce
的基本概念,以及它们在大数据处理中的重要性。然后,我们将逐步指导读者如何在多节点环境中部署
Hadoop
集群
,包括硬件和软件的配置,以及如何解决可能遇到的问题。接下来,我们将介绍如何在
Hadoop
集群
上
运行
MapRed
uce
任务,包括编写
MapRed
uce
程序,配置任务,以及监控任务的执行。最后,我们将分享一些优化
Hadoop
集群
性能和
MapRed
uce
任务效率的技巧和建议。
在
hadoop
运行
MapRed
uce
失败
原因
及其解决方法
在
hadoop
运行
MapRed
uce
失败
原因
及其解决方法 刚开始接触在
hadoop
集群
上
运行
MapRed
uce
,但由于自己能力有限,一开始
运行
时
遇见了各种各样的bug,最终靠重装
hadoop
解决了所有问题。 本文便是对之前遇见的各种各样bug进行一个总结 错误一: 在输入完指令:
hadoop
jar original-wordcount-1.0-SNAPSHOT.jar remove.TestWordCount 出现 错误提示:拒绝连接
原因
: 可能是因为之前
运行
的
时
候不小心打开了slave1
Hadoop
基础操作--
运行
MapRed
uce
任务
一、了解
Hadoop
的示例程序包: 在本地目录中“$
HADOOP
_HOME/share/
hadoop
/
mapred
uce
"下可以发现一个名为”
hadoop
-
mapred
uce
-examples-2.6.4.jar"的示例程序包(我这里的
Hadoop
版本是2.6.4,所以程序包也是2.6.4),这个程序包里有一些自带的测试模块,这里我就不都列举了,可以自己查看自己的程序包下面的测试模块。其中wordcount适合对文件的数据进行登录次数的统计。 二、提交
MapRed
uce
任务给
集群
运行
...
Informatica
246
社区成员
377
社区内容
发帖
与我相关
我的任务
Informatica
讨论 Informatica 数据集成相关技术、数据隐私保护相关技术
复制链接
扫一扫
分享
社区描述
讨论 Informatica 数据集成相关技术、数据隐私保护相关技术
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享