


6,129
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM emp WHERE deptno=66 OR JOB='sals'
--2.1 两者用的是 OR, 条件列与索引不匹配
SELECT * FROM emp WHERE deptno=66
UNION
SELECT * FROM emp WHERE JOB='sals'
--2.2 改良后的写法,有一个语句是索引查找
/*
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
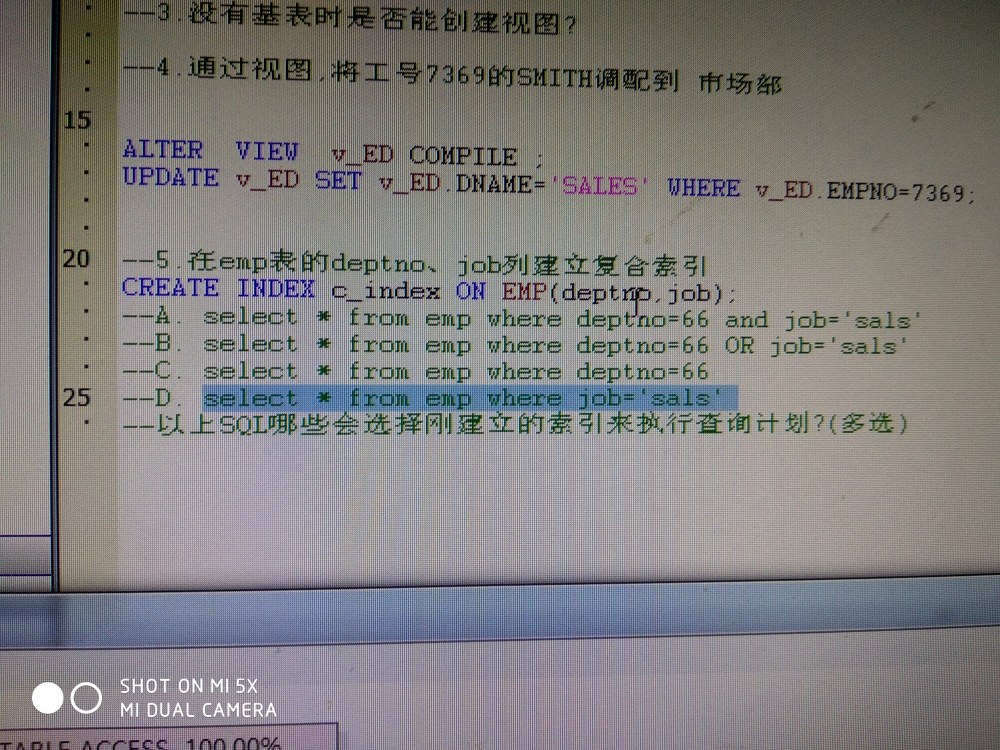
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(1 行受影响)
表 'EMP'。扫描计数 5,逻辑读取 14811 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 640 毫秒,占用时间 = 170 毫秒。
(1 行受影响)
表 'EMP'。扫描计数 6,逻辑读取 14814 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 438 毫秒,占用时间 = 113 毫秒。
*/
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM emp WHERE deptno=66 OR JOB='sals'
--2.1 两者用的是 OR, 条件列与索引不匹配
SELECT * FROM emp WHERE deptno=66
UNION
SELECT * FROM emp WHERE JOB='sals'
--2.2 改良后的写法,有一个语句是索引查找
/*
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(1 行受影响)
表 'EMP'。扫描计数 5,逻辑读取 14811 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 640 毫秒,占用时间 = 170 毫秒。
(1 行受影响)
表 'EMP'。扫描计数 6,逻辑读取 14814 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 438 毫秒,占用时间 = 113 毫秒。
*/
USE tempdb
GO
IF OBJECT_ID('EMP') IS NOT NULL
DROP TABLE EMP
GO
CREATE TABLE EMP(
id INT IDENTITY(1,1) PRIMARY KEY,
deptno INT,
job VARCHAR(20)
)
GO
INSERT INTO EMP(deptno,[job])
SELECT ROW_NUMBER() OVER (ORDER BY(SELECT 1)) AS rid
,left(NEWID(),10) AS job
FROM [master].dbo.spt_values AS sv
CROSS JOIN [master].dbo.spt_values AS sv2
WHERE sv.type='P' AND sv2.type='P' AND sv.number>0 AND sv2.number>0
--(4190209 行受影响)
CREATE INDEX c_index ON EMP(deptno,job)
--------- 以上为测试表及数据 ----------
--执行,打开执行计划
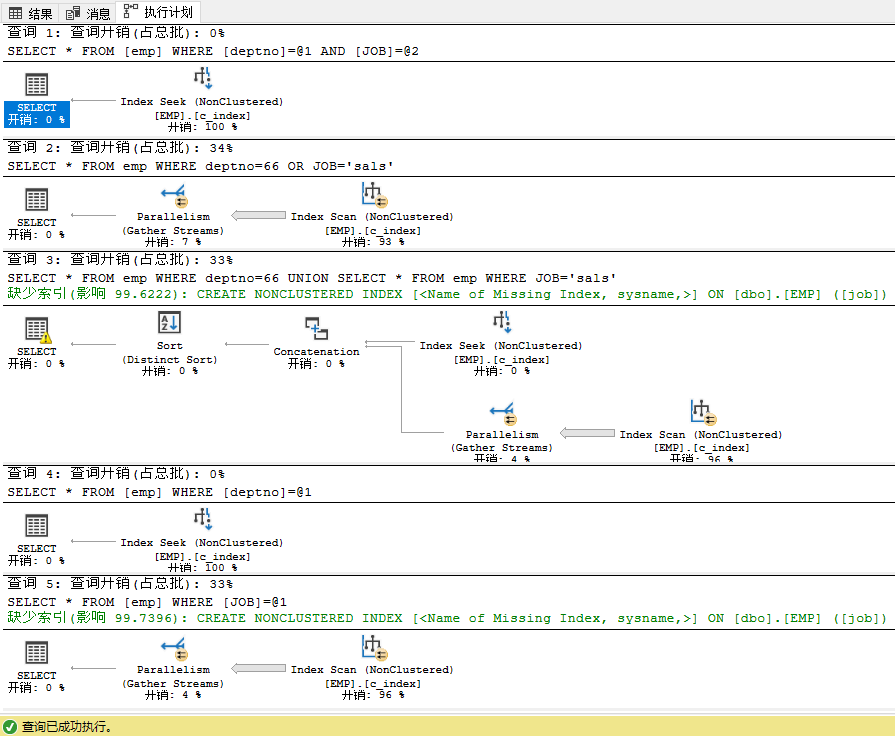
SELECT * FROM emp WHERE deptno=66 AND JOB = 'sals'
--1. 两者用的是 AND, 条件列与索引正好匹配
SELECT * FROM emp WHERE deptno=66 OR JOB='sals'
--2.1 两者用的是 OR, 条件列与索引不匹配
SELECT * FROM emp WHERE deptno=66
UNION
SELECT * FROM emp WHERE JOB='sals'
--2.2 改良后的写法,有一个语句是索引查找
SELECT * FROM emp WHERE deptno=66
--3. 首列匹配,所以是索引查找
SELECT * FROM emp WHERE JOB='sals'
--4. 首列不匹配
