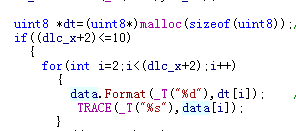
CString strOut; for(int i=0; i<Nums; i++) { CString s; s.Format(_T("%d,"), dt[i]); strOut += s; }
15,979
社区成员
115,897
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享