

34,838
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享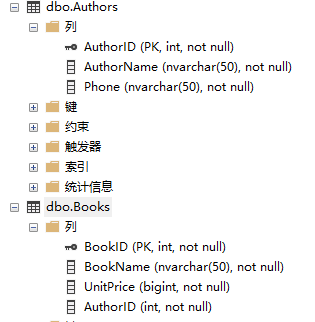
select b.*,a.* from Books b inner join Authors a on b.AuthorID=a.AuthorID
create proc usp_Books_GetBooks
as
begin
DECLARE @t_Books table
(
BookId int,
BookName nvarchar(50),
UnitPrice bigint,
AuthorID int
);
insert into @t_Books select b.BookID,b.BookName,b.UnitPrice,b.AuthorID from Books b;
DECLARE @t_Authors table
(
AuthorID int,
AuthorName nvarchar(50)
);
insert into @t_Authors select a.AuthorID,a.AuthorName from Authors a where a.AuthorID in(select t_Books.AuthorID from @t_Books t_Books);
select t_Books.*,t_Authors.* from @t_Books t_Books inner join @t_Authors t_Authors on t_Authors.AuthorID=t_Books.AuthorID;
end
create proc usp_Books_GetBooks_1
as
begin
DECLARE @t_Books table
(
BookId int,
BookName nvarchar(50),
UnitPrice bigint,
AuthorID int
);
insert into @t_Books select b.BookID,b.BookName,b.UnitPrice,b.AuthorID from Books b;
select a.AuthorID,a.AuthorName from Authors a where a.AuthorID in(select t_Books.AuthorID from @t_Books t_Books);
select * from @t_Books;
end







