社区
CSS
帖子详情
如何爬取网站里符合要求的所有图片
兔兔土土
2019-06-11 02:33:13
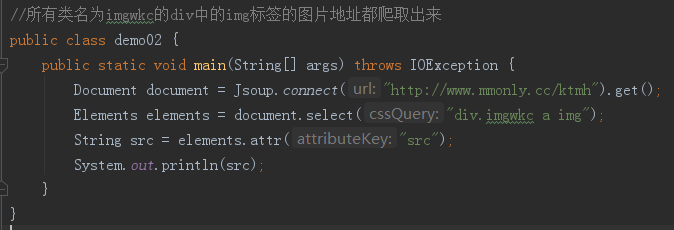
小弟的代码只爬取了第一个地址,如何爬取本页面所有图片地址呢?
...全文
219
2
打赏
收藏
如何爬取网站里符合要求的所有图片
小弟的代码只爬取了第一个地址,如何爬取本页面所有图片地址呢?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
叮咚呛咚呛
2019-06-25
打赏
举报
回复
老铁,Elements是一个集合 你要遍历才行哦遍历用Element接收 类似这样: Elements els = doc.select(".imgwkc img"); for(int i =0;i<els.size();i++){ Element el = els.get(i); String src = el.attr("src"); System.out.print(src); }
兔兔土土
2019-06-11
打赏
举报
回复
构网型变流器正负序阻抗解耦特性及扫频验证研究(Simulink仿真实现)
内容概要:本文系统研究了构网型变流器的正负序阻抗解耦特性及其在弱电网环境下的稳定性表现,重点依托Matlab/Simulink仿真平台,构建了详细的阻抗数学模型,设计了解耦控制策略,并采用小信号扫频法进行频域辨识与稳定性验证。研究深入探讨了构网型变流器与传统跟网型逆变器在正负序阻抗特性上的本质差异,结合虚拟同步发电机(VSG)等先进控制技术,分析其在抑制宽频带振荡、削弱锁相环动态耦合等方面的优越性。文中不仅提供了完整的仿真模型与MATLAB代码实现,还整合了光伏、风电、储能、微电网等多类新能源系统的阻抗建模与稳定性分析资源,形成了一套面向新型电力系统稳定性的综合性技术资料体系,具有较强的科研复现与工程参考价值。; 适合人群:面向具备电力电子、电力系统自动化、新能源并网等专业背景的研究生、高校教师及工程技术人员,特别适用于从事阻抗建模、小干扰稳定性分析、宽频振荡机理研究以及撰写高水平学术论文的科研工作者。; 使用场景及目标:①掌握构网型变流器正负序阻抗建模与扫频辨识的仿真方法;②深入理解VSG等构网型控制在弱电网中提升稳定性的内在机理;③复现顶刊论文中的阻抗分析流程与稳定性判据应用;④利用提供的成熟模型与代码加速科研进程,支撑课题研究与学术成果产出。; 阅读建议:建议结合文中提供的Simulink模型与MATLAB代码,按照“理论建模—仿真搭建—扫频激励—频响提取—Nyquist判据分析”的完整流程进行实践操作,重点关注扫频信号的注入方式、频率范围设置及阻抗曲线的物理意义解读,并参考博士论文复现案例深化对复杂动态耦合问题的理解。
科技中介服务机构如何在区域科技创新数智大脑中提升服务效能?.docx
科易网基于40亿+科创知识图谱数据库,深度探索AI技术在技术转移、成果转化、技术经纪、知识产权、产业创新、科技招商等垂直领域的多样化应用场景,研究科技创新领域的AI+数智化解决方案,推动科技创新与产业创新智能化发展。
AgentAtlas:AI 编程项目的全景地图
AgentAtlas:AI 编程项目的全景地图
弱电网下虚拟同步发电机正负序阻抗建模仿真(Simulink仿真实现)
内容概要:本文围绕弱电网条件下虚拟同步发电机(VSG)的正负序阻抗建模与稳定性分析展开,利用Simulink搭建仿真模型,系统研究VSG在不对称电网环境下的动态响应特性。通过构建正负序阻抗模型,深入分析其在弱电网接入时的阻抗特性演变规律,并结合扫频法进行仿真验证,揭示VSG与电网之间的交互稳定性机理,为新能源并网系统的稳定运行提供理论支持和技术路径。研究涵盖控制策略对阻抗特性的影响、序阻抗建模方法及稳定性判据应用,具有较强的工程实践价值。; 适合人群:具备电力电子、电力系统分析基础知识,从事新能源并网、微电网控制、VSG技术研究的研究生、科研人员及工程技术人员。; 使用场景及目标:① 掌握虚拟同步发电机在弱电网条件下的正负序阻抗建模方法;② 学习基于Simulink的扫频法仿真技术,用于分析并网系统稳定性;③ 深入理解VSG控制参数对系统稳定性的关键影响,支撑科研论文复现与创新研究; 阅读建议:建议结合相关博士论文及期刊文献,按照文档目录顺序逐步学习,重点动手实践Simulink模型搭建与扫频仿真流程,结合理论推导深化对阻抗建模与稳定性分析的理解。
科技中介服务机构如何依托科创数智大脑提升服务精准度与客户粘性?.docx
科易网基于40亿+科创知识图谱数据库,深度探索AI技术在技术转移、成果转化、技术经纪、知识产权、产业创新、科技招商等垂直领域的多样化应用场景,研究科技创新领域的AI+数智化解决方案,推动科技创新与产业创新智能化发展。
CSS
61,120
社区成员
60,701
社区内容
发帖
与我相关
我的任务
CSS
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
复制链接
扫一扫
分享
社区描述
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
