社区
CSS
帖子详情
如何爬取网站里符合要求的所有图片
兔兔土土
2019-06-11 02:33:13
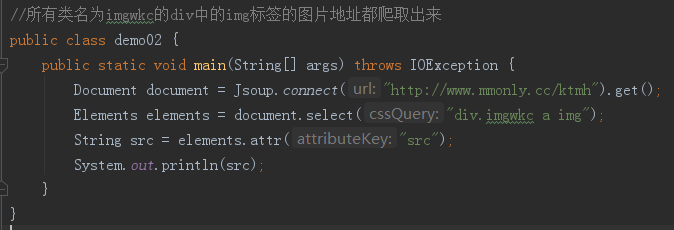
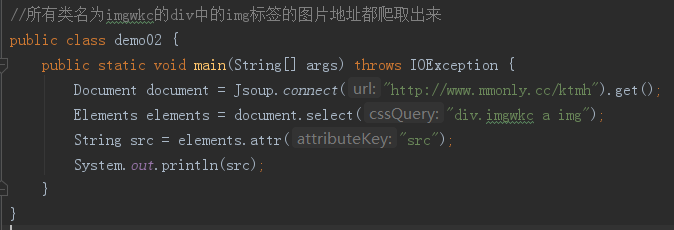
小弟的代码只爬取了第一个地址,如何爬取本页面所有图片地址呢?
...全文
147
2
打赏
收藏
如何爬取网站里符合要求的所有图片
小弟的代码只爬取了第一个地址,如何爬取本页面所有图片地址呢?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
叮咚呛咚呛
2019-06-25
打赏
举报
回复
老铁,Elements是一个集合 你要遍历才行哦遍历用Element接收 类似这样: Elements els = doc.select(".imgwkc img"); for(int i =0;i<els.size();i++){ Element el = els.get(i); String src = el.attr("src"); System.out.print(src); }
兔兔土土
2019-06-11
打赏
举报
回复
观察网新闻
爬取
爬取
观察网所有新闻,运用python3的多线程,首先正则表达式匹配网址,
爬取
所有观察网
符合要求
的新闻,然后处理其中的
图片
、文字,把标题、新闻内容、发表时间、作者、评论数、阅读数等存入数据库,可用于舆情监督...
Python爬虫
爬取
壁纸示例
定制筛选条件:根据个人需要,可以增加一些筛选条件,如壁纸类型、分辨率、色彩等,以便更精确地
爬取
符合要求
的壁纸。 设置延时和异常处理:为了避免对目标
网站
的过度访问,可以设置合适的延时,以及处理可能出现的...
myCrawler:我的爬虫练习
因为有些数据的格式不
符合要求
,实际
爬取
数量为60000+。稍作修改,可以拓展功能,或者做些其他有趣的事情。bookCrawler3上一个爬虫的全面升级。只
爬取
“编程”标签下的书籍,但这次
爬取
了书籍详情页面和书籍
图片
,...
Python爬虫练习笔记——
爬取
单个网页
里
的所有
图片
(入门)
先从简单的练习开始吧~
爬取
单个网页
里
的所有
图片
,这个没有什么难点,因为不需要翻页哈哈哈哈 我很喜欢一些文章中的配图,比如这篇,
里
面就会有很多电影中的经典截图 第一步:分析网页 1.首先我们要了解要
爬取
网站
...
利用img请求一个html页面,爬虫学习笔记——
爬取
单个网页
里
的所有
图片
(入门)...
最近闲着,想学一下爬虫 (^-^)V ——[手动比耶]先从简单的练习开始吧~
爬取
单个网页
里
的所有
图片
,这个没有什么难点,因为不需要翻页哈哈哈哈。我很喜欢一些文章中的配图,比如这篇,
里
面就会有很多电影中的经典...
CSS
61,112
社区成员
60,730
社区内容
发帖
与我相关
我的任务
CSS
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
复制链接
扫一扫
分享
社区描述
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章






 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
