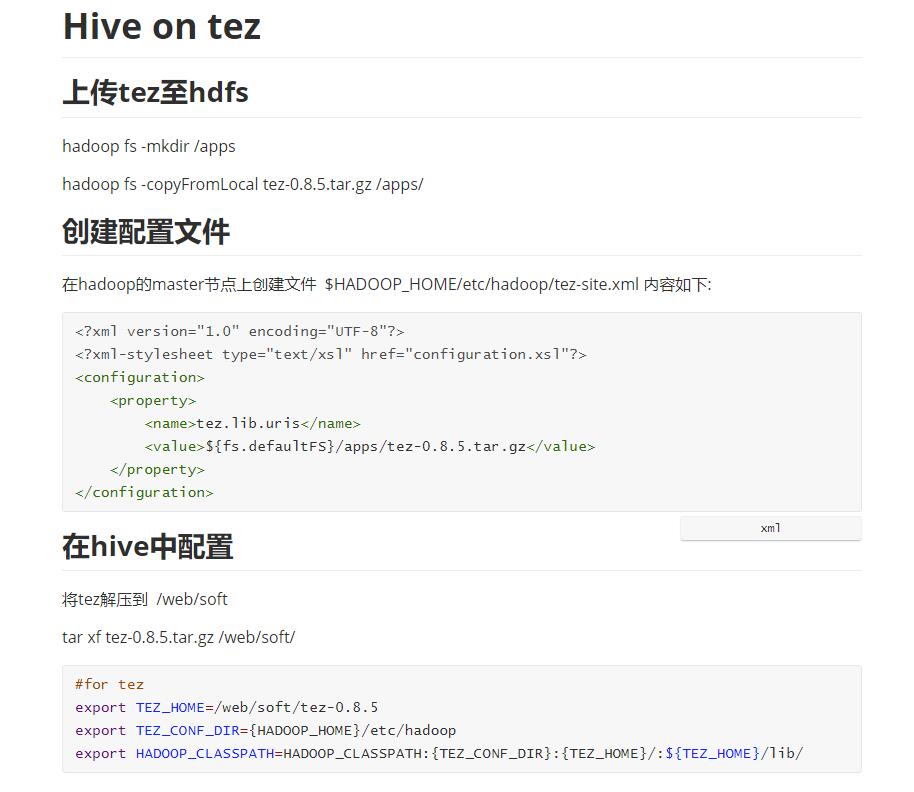
首先是软件版本信息
 下面是我的配置方法
下面是我的配置方法
select * from predict_als ,正常
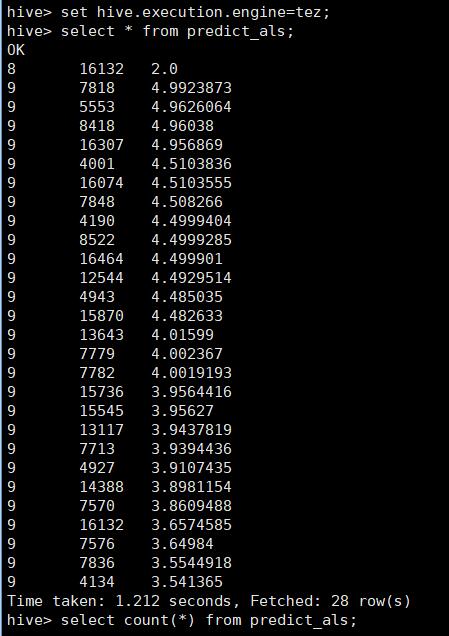
select count(*) from predict_als; 报错

下面是诊断信息
User: hadoop
Name: HIVE-78752bfe-7a07-402a-b6e4-15044a862316
Application Type: TEZ
Application Tags:
YarnApplicationState: FAILED
FinalStatus Reported by AM: FAILED
Started: 21-Jun-2019 18:20:54
Elapsed: 44sec
Tracking URL: History
Diagnostics: Application application_1561112432699_0001 failed 2 times due to AM Container for appattempt_1561112432699_0001_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://IPTV-Recommend1:8088/proxy/application_1561112432699_0001/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1561112432699_0001_02_000001
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:575)
at org.apache.hadoop.util.Shell.run(Shell.java:478)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:766)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Container exited with a non-zero exit code 1
Failing this attempt. Failing the application.
# hive详细日志
2019-06-21T18:20:54,800 INFO [main] client.TezClient: Session mode. Starting session.
2019-06-21T18:20:54,800 INFO [main] client.TezClientUtils: Using tez.lib.uris value from configuration: hdfs://HN3/apps/tez-0.8.5.tar.gz
2019-06-21T18:20:54,800 INFO [main] client.TezClientUtils: Using tez.lib.uris.classpath value from configuration: null
2019-06-21T18:20:54,823 INFO [main] client.TezClient: Tez system stage directory hdfs://HN3/tmp/hive/hadoop/_tez_session_dir/78752bfe-7a07-402a-b6e4-15044a862316/.tez/application_1561112432699_0001 doesn't exist and is created
2019-06-21T18:20:55,153 INFO [main] impl.YarnClientImpl: Submitted application application_1561112432699_0001
2019-06-21T18:20:55,155 INFO [main] client.TezClient: The url to track the Tez Session: http://IPTV-Recommend1:8088/proxy/application_1561112432699_0001/
2019-06-21T18:21:39,812 INFO [main] client.TezClient: App did not succeed. Diagnostics: Application application_1561112432699_0001 failed 2 times due to AM Container for appattempt_1561112432699_0001_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://IPTV-Recommend1:8088/proxy/application_1561112432699_0001/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1561112432699_0001_02_000001
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:575)
at org.apache.hadoop.util.Shell.run(Shell.java:478)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:766)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Container exited with a non-zero exit code 1
Failing this attempt. Failing the application.
2019-06-21T18:21:39,812 ERROR [main] exec.Task: Failed to execute tez graph.
org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1561112432699_0001 failed 2 times due to AM Container for appattempt_1561112432699_0001_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://IPTV-Recommend1:8088/proxy/application_1561112432699_0001/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1561112432699_0001_02_000001
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:575)
at org.apache.hadoop.util.Shell.run(Shell.java:478)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:766)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

