社区
Hadoop生态社区
帖子详情
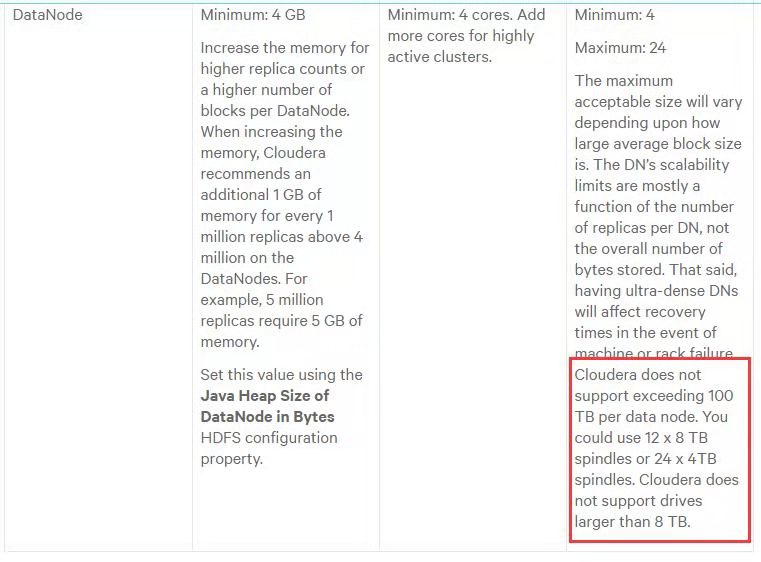
cloudera 官网描述CDH6部署hadoop数据节点datanode不能用大于8T的硬盘?
csMRdn
2019-07-19 10:04:51
每个节点硬盘总容量不超过100T, 为什么不支持大于8T 的硬盘,用了10T的会怎么样?
...全文
45
回复
打赏
收藏
cloudera 官网描述CDH6部署hadoop数据节点datanode不能用大于8T的硬盘?
每个节点硬盘总容量不超过100T, 为什么不支持大于8T 的硬盘,用了10T的会怎么样?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
RPC-Heat-HDP:在Rackspace私有云上
部署
Apache
Hadoop
热模板
将来可能会增加对Apache
Hadoop
和
Cloudera
CDH发行版以及
Hadoop
YARN的支持。 该模板使用配置服务器。 它
部署
了一个盐大师,以及许多盐小兵。 一小部分将是
Hadoop
主
节点
。 其余的奴才将是
Hadoop
数据
节点
。 可以在...
大
数据
面试题-.docx
Cloudera
CDH 是需要付费使用的。( ) 18.
Hadoop
是 Java 开发的,所以 MapReduce 只支持 Java 语言编写。( ) 19.
Hadoop
支持
数据
的随机读写。( ) 20. Name
Node
负责管理 meta
data
,client 端每次读写请求,它都会...
CDH6
.x企业级大
数据
平台搭建
实战演练基于
Cloudera
Manager(
CDH6
)安装
部署
、监控管理、运营维护大
数据
平台的各个服务组件。从理论经验到实战演练,从设计思想到流程实施,亲力亲测,你也绝对可以。推荐进阶课程:大
数据
运维尖刀班
大
数据
面试题.doc
Cloudera
CDH 是需要付费使用的。( ) 18.
Hadoop
是 Java 开发的,所以 MapReduce 只支持 Java 语言编写。( ) 19.
Hadoop
支持
数据
的随机读写。( ) 20. Name
Node
负责管理 meta
data
,client 端每次读写请求,它都会...
大
数据
面试题(1).doc
Cloudera
CDH 是需要付费使用的。( ) 18.
Hadoop
是 Java 开发的,所以 MapReduce 只支持 Java 语言编写。( ) 19.
Hadoop
支持
数据
的随机读写。( ) 20. Name
Node
负责管理 meta
data
,client 端每次读写请求,它都会...
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享