社区
Hadoop生态社区
帖子详情
怎么样解决HIve跑批大约一个星期后会变得很慢的问题
flyaga
2019-07-22 11:52:25
HIve跑批大约一个星期后会变得很慢,需要重启CDH Hadoop集群后,跑批才能够正常,请问是什么原因造成这样的问题?需要怎么样才能够跑批正常?谢谢!
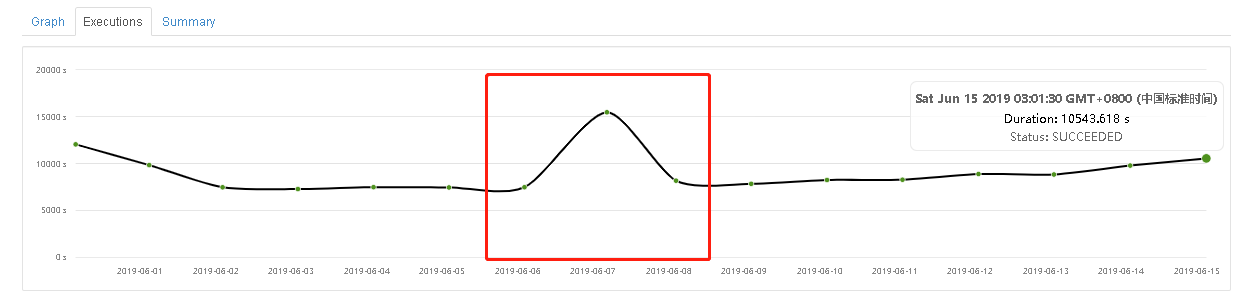
红框处是重启了CDH Hadoop集群,重启后跑批时间正常
开始以为是Hdfs临时目录下文件太多的问题,开启定时程序删除了3天前的临时文件,但没有效果,问题还是存在。
...全文
149
回复
打赏
收藏
怎么样解决HIve跑批大约一个星期后会变得很慢的问题
HIve跑批大约一个星期后会变得很慢,需要重启CDH Hadoop集群后,跑批才能够正常,请问是什么原因造成这样的问题?需要怎么样才能够跑批正常?谢谢! 红框处是重启了CDH Hadoop集群,重启后跑批时间正常 开始以为是Hdfs临时目录下文件太多的问题,开启定时程序删除了3天前的临时文件,但没有效果,问题还是存在。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
hive
--map数量过小导致
hive
运行缓慢
map数量过小导致
hive
运行缓慢 查看脚本发现 参数
hive
sql基本操作
hive
基本语法10/11––dbeaver链接
hive
的办法:如果vscode上面有做端口映射 可以直接使用localhost登录;如果没有做端口映射,需要用主机ip地址登录–dbeaver链接mysql的办法:先在vscode上面有做端口映射 再根据映射的端口登录即可--只会删除元数据(mysql的数据)–删除数据库 加上cascade关键字会做级联删除,把数据库以及数据库下的所有表跟内容都删除掉–而且 会同时mysql上的元数据跟hdfs上的文件内容;
数据分析从零到精通第二课
Hive
和Spark入门
03 离线利器:大数据离线处理工具
Hive
的常用技巧 今天为你介绍数据分析师最常用的数据处理工具
Hive
的一些使用技巧。这些技巧我们在工作中使用得比较频繁,如果运用得当,将为我们省去不少时间精力。 那么首先,我们先来了解下
Hive
。
Hive
是 Facebook 开源的一款基于 Hadoop 的数据仓库工具,它能完美支持 SQL 查询功能,将 SQL 查询转变为 MapReduce 任务执行。这使得大数据统计得以实现。
Hive
是最早的也是目前应用最广泛的大数据处理
解决
方案。
Hive
的重要性
CDP中的
Hive
3系列之
Hive
3使用指南
在了解了Apache
Hive
3的特性和启动
Hive
后,就需要了解如何使用Apache
Hive
3.
hive
数据仓库-
Hive
1. 数据仓库 1.1. 基本概念 英文名称为Data Warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。 数据仓库是存数据的,企业的各种数据往里面存,主要目的是为了分析有效数据,后续会基于它产出供分析挖掘的数据,或者数据应用需要的数据,如企业的分析性报告和各类报表等。 可以理解为:面...
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
