初学者使用scrapy spiders爬取某网站的数据,遇到一个问题。
情况是这样的,我要爬取的是一个返回数据的接口,我可以入参pageSize和pageNumber来控制返回数据量的多少。
由于总数据量3W多条,于是使用Size=1000(返回1000条数据),结果大部分请求超过3分钟超时了(scrapy默认超时时间为180S),我怀疑过是否是因为返回数据太大导致scrapy底层处理response对象耗时太久了,但是等我使用requests.get(url)后,我发现原来是接口服务端处理时间比较长。
在使用requests请求查找问题时,自己做了时间和数据大小输出,情况如下:
当size=10时
耗时: 0:00:20.995203
当返回 10 条数据时,数据量大小:17.846 kb
当size=100时
耗时: 0:00:48.262390
当返回 100 条数据时,数据量大小:189.148 kb
当size=1000时
耗时: 0:04:12.454073
当返回 1000 条数据时,数据量大小:1980.934 kb
看到当查询1000条数据要花费4分钟12秒时,我有点茫然,3W条数据至少要30次请求,也就是至少要耗时126分钟,再加上connect和disconnect的时间,这有点消耗不起啊。
我用scrapy跑起来,感觉好像是单线程,上一个请求必须结束下一个请求才起,该如何使他并发请求以节约时间呢。
因为初学,还搞不太清楚下载器等等其他的组件如何使用,现在代码全在spider.py中跑,也没有用到其他组件,代码如下图:
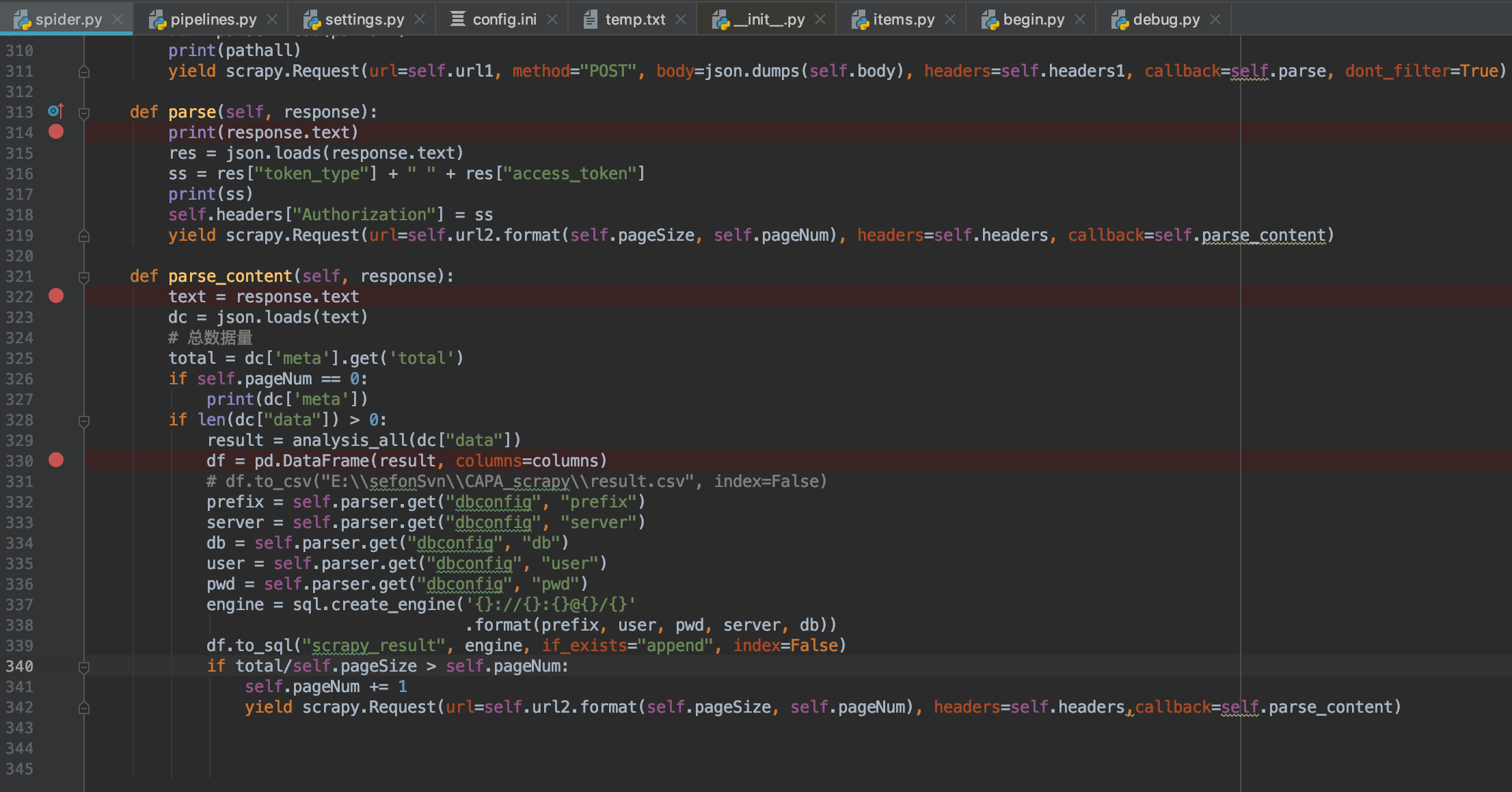
请大家指点一下,如何提高效率。


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

