


22,210
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


 [/quote]结帖结帖
[/quote]结帖结帖 [/quote]
明天结帖,手机不能结帖
[/quote]
明天结帖,手机不能结帖 [/quote]结帖结帖
[/quote]结帖结帖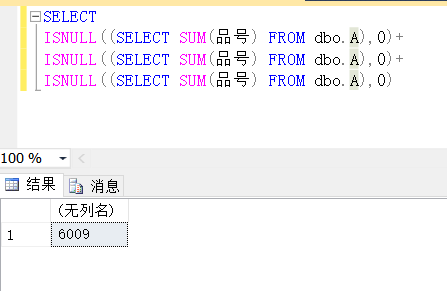 [/quote]
我的sql server如果是oracle就好了[/quote]
我的也是sqlserver[/quote]
我想问,如果是查一个表,怎么嵌套结果到主表[/quote]
我的sql server如果是oracle就好了[/quote]
我的也是sqlserver[/quote]
我的sql server如果是oracle就好了
[/quote]
我的sql server如果是oracle就好了[/quote]
我的也是sqlserver[/quote]
我想问,如果是查一个表,怎么嵌套结果到主表[/quote]
我的sql server如果是oracle就好了[/quote]
我的也是sqlserver[/quote]
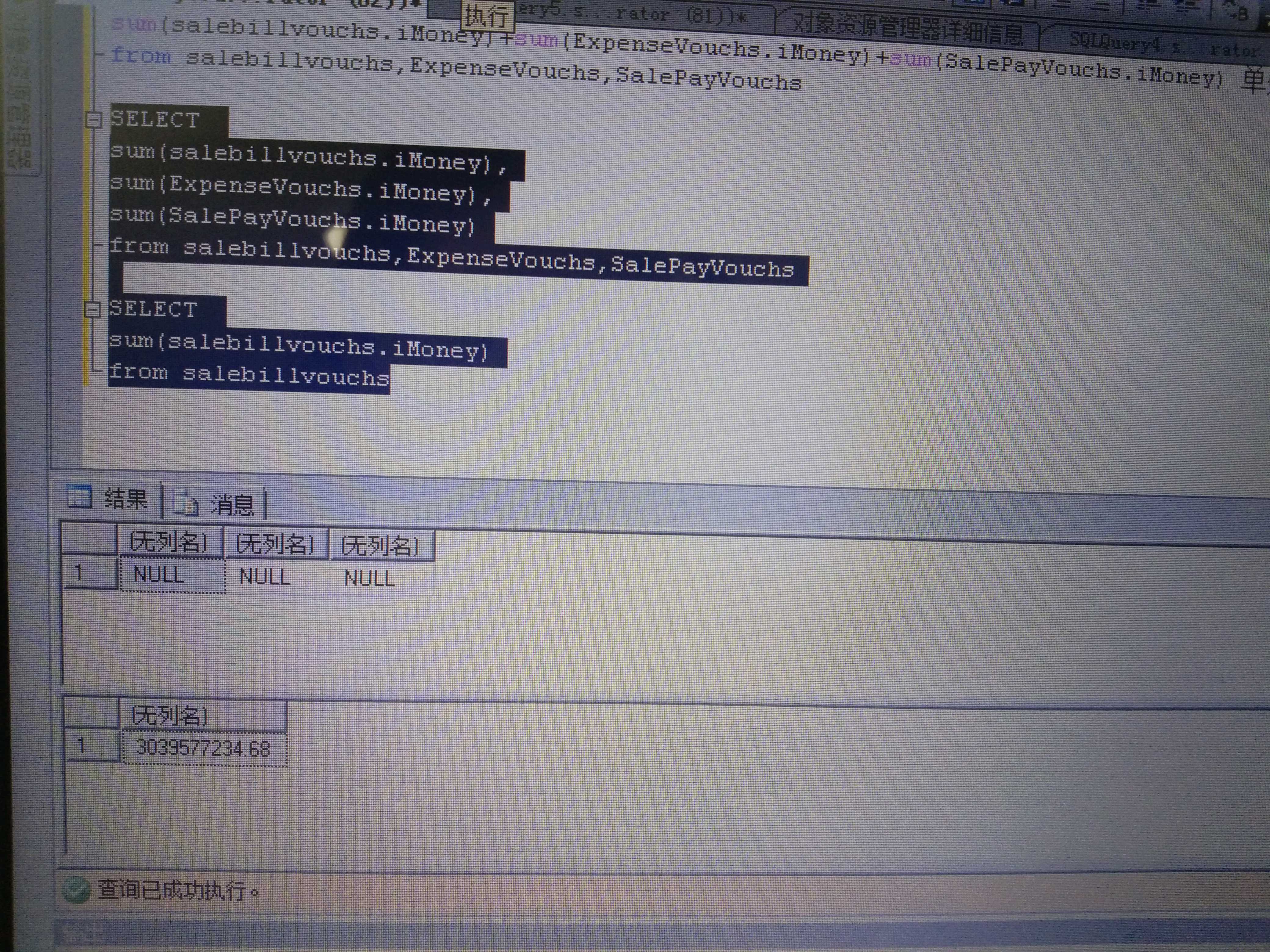
我的sql server如果是oracle就好了SELECT
ISNULL((SELECT SUM(imoney) FROM 表1),0)+
ISNULL((SELECT SUM(imoney) FROM 表2),0)+
ISNULL((SELECT SUM(imoney) FROM 表3),0)SELECT
(SELECT SUM(imoney) FROM 表1)+
(SELECT SUM(imoney) FROM 表2)+
(SELECT SUM(imoney) FROM 表3)SELECT
(SELECT SUM(imoney) FROM 表1)+
(SELECT SUM(imoney) FROM 表2)+
(SELECT SUM(imoney) FROM 表3)

select s1=(select sum([表1字段]) from [表1]),
s2=(select sum([表2字段]) from [表2]),
s3=(select sum([表3字段]) from [表3])
SELECT
(SELECT SUM(imoney) FROM 表1),
(SELECT SUM(imoney) FROM 表2),
(SELECT SUM(imoney) FROM 表3)


