65,170
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







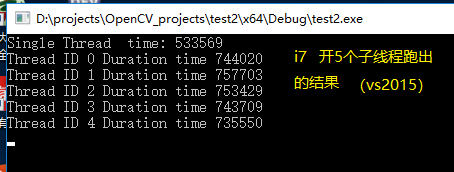
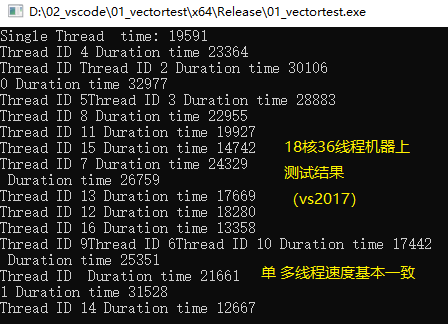
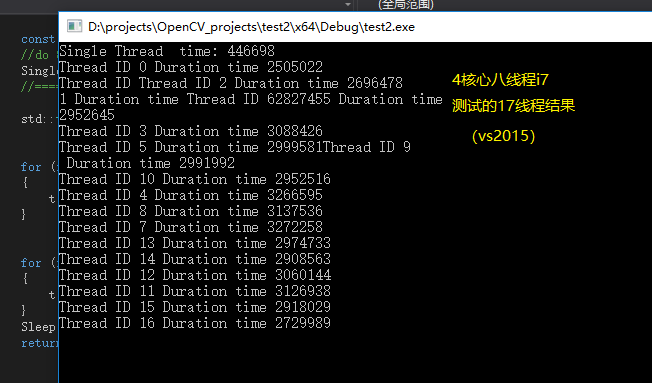 我使用的电脑的vs升级到2017之后,万万没有想到是编译器的锅,速度得到改善,单多线程压80万次数据,速度基本一致,测试代码链接为
http://coliru.stacked-crooked.com/a/ac6511016bf5d29a
我使用的电脑的vs升级到2017之后,万万没有想到是编译器的锅,速度得到改善,单多线程压80万次数据,速度基本一致,测试代码链接为
http://coliru.stacked-crooked.com/a/ac6511016bf5d29a
 感谢各位前辈出谋划策,谢谢大家帮助!
感谢各位前辈出谋划策,谢谢大家帮助!
 因为我存放的数量其实是不确定的,用内置数组觉得很有可能会溢出或者浪费,80万个数据只是我预估的数量写demo测试的,目前基本确定是编译器的锅了,vs2015社区版换成vs2017之后表现稳定,单多基本上速度一致
因为我存放的数量其实是不确定的,用内置数组觉得很有可能会溢出或者浪费,80万个数据只是我预估的数量写demo测试的,目前基本确定是编译器的锅了,vs2015社区版换成vs2017之后表现稳定,单多基本上速度一致 [/quote]
不要让线程数超过物理核心数。也不要让每个线程都分配80万数据。例如你有8个线程,那么每个线程应该是10万数据才对。
如果每线程10万×8线程,仍然跑不过每线程80万×单线程,那瓶颈就在于内存读写。你计算量很小,大部分操作都是在随机、跳跃地进行内存访问。如果你每emplace一个元素之前,都加上一顿复杂数学计算,比如算个MD5或者算个圆周率,那么估计多线程的表现一定会好于单线程。[/quote]嗯嗯 我的代码其实在for前会有一系列的矩阵运算,for后也会对读出的容器里面的值进行矩阵运算,计算量还是有的,最新的实验是,我将容器提前进行resize固定,然后用下标修改值,速度就和单线程一致了,如果是内存的访问费时间,为什么单线程或者线程少的时候速度却快呢?难道是多cpu核心把"内存条带宽满了"或"抢先内存总线"什么的?可是这种情况下,是cpu一直参与么,感觉cpu不是该把指令发过去然后在等待就好了么?可“执行”占比一直是高比例的,说明cpu一直在“算”什么东西吧? 我对这个底层的原理一知半解的,我还在查这边的资料。这里我就是瞎猜,其实也是想记录一下思路,说得多,前辈不要见怪哈~ 我现在想从vector源码找找思路,看到底为什么这样子[/quote]
容器这么大规模频率插入,内存扩展不做优化,速度肯定慢的。
申请内存从用户操作切到内核操作,多线程申请内存需要竞争的,不然还不乱套了。
用户到内核切换需要花时间,申请内存竞争,多线程肯定慢了。
多核的优势在于利用cpu的计算能力,如果你没有抓住这个重点,合理榨取硬件性能。
单纯认为多线程就能多快好省是一种误区。
[/quote]
不要让线程数超过物理核心数。也不要让每个线程都分配80万数据。例如你有8个线程,那么每个线程应该是10万数据才对。
如果每线程10万×8线程,仍然跑不过每线程80万×单线程,那瓶颈就在于内存读写。你计算量很小,大部分操作都是在随机、跳跃地进行内存访问。如果你每emplace一个元素之前,都加上一顿复杂数学计算,比如算个MD5或者算个圆周率,那么估计多线程的表现一定会好于单线程。[/quote]嗯嗯 我的代码其实在for前会有一系列的矩阵运算,for后也会对读出的容器里面的值进行矩阵运算,计算量还是有的,最新的实验是,我将容器提前进行resize固定,然后用下标修改值,速度就和单线程一致了,如果是内存的访问费时间,为什么单线程或者线程少的时候速度却快呢?难道是多cpu核心把"内存条带宽满了"或"抢先内存总线"什么的?可是这种情况下,是cpu一直参与么,感觉cpu不是该把指令发过去然后在等待就好了么?可“执行”占比一直是高比例的,说明cpu一直在“算”什么东西吧? 我对这个底层的原理一知半解的,我还在查这边的资料。这里我就是瞎猜,其实也是想记录一下思路,说得多,前辈不要见怪哈~ 我现在想从vector源码找找思路,看到底为什么这样子[/quote]
容器这么大规模频率插入,内存扩展不做优化,速度肯定慢的。
申请内存从用户操作切到内核操作,多线程申请内存需要竞争的,不然还不乱套了。
用户到内核切换需要花时间,申请内存竞争,多线程肯定慢了。
多核的优势在于利用cpu的计算能力,如果你没有抓住这个重点,合理榨取硬件性能。
单纯认为多线程就能多快好省是一种误区。