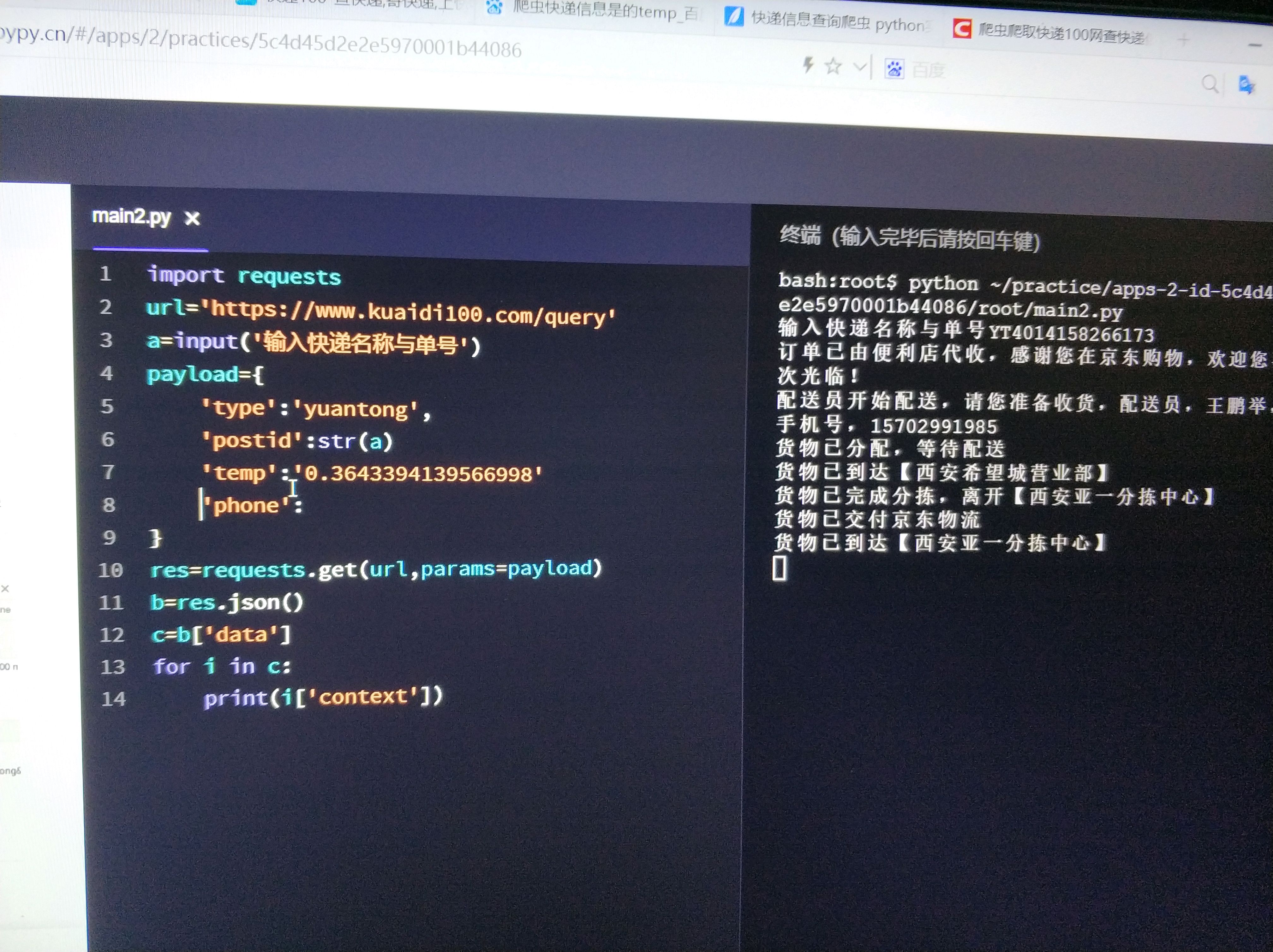
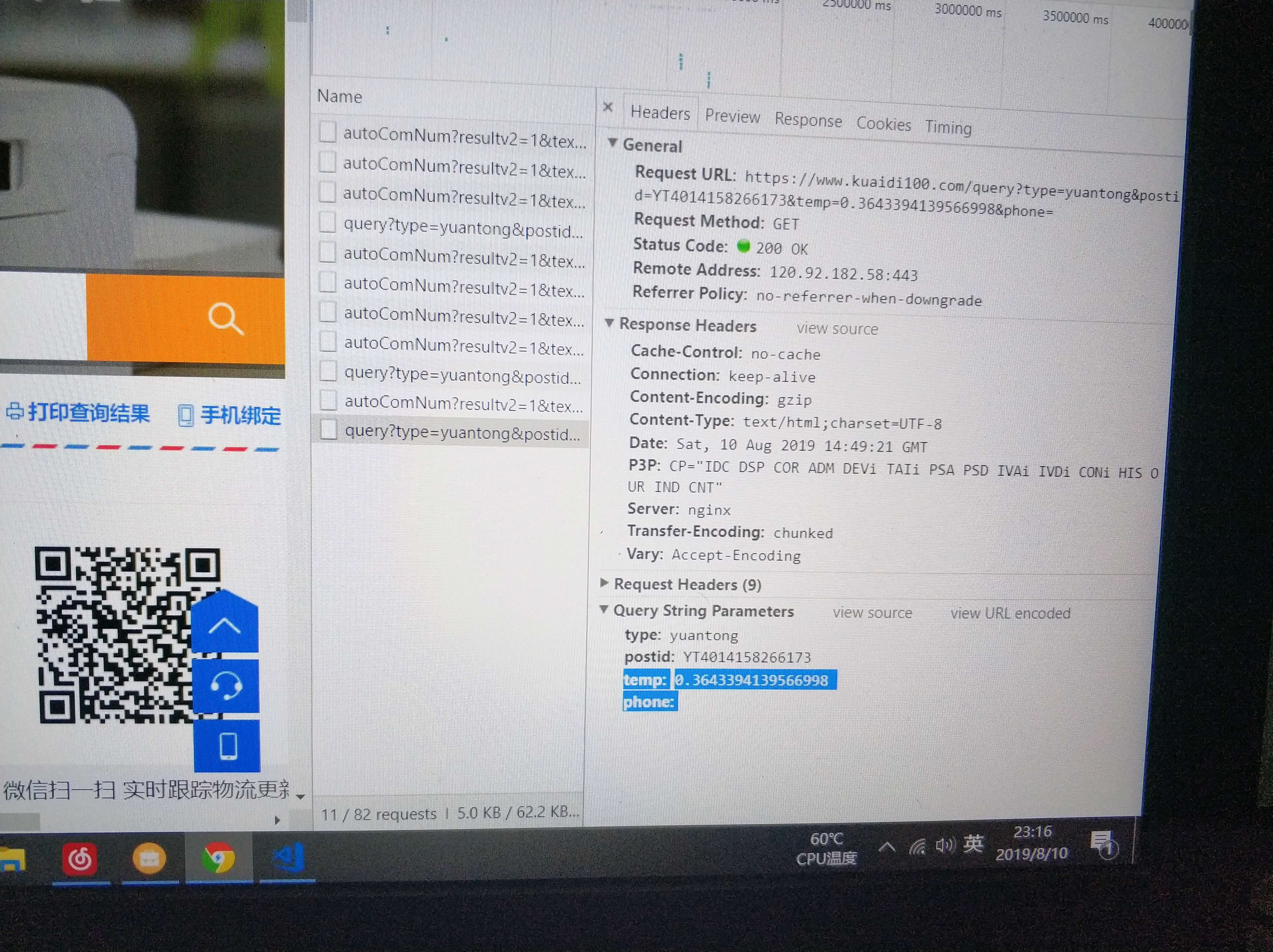
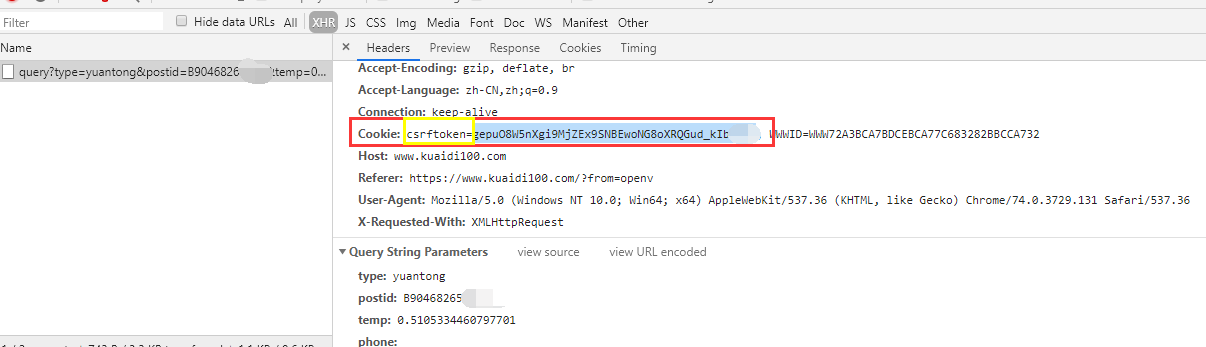
另外一个不需要更新cookie的办法,是使用到第8关的内容,request.get首页获取cookie,再用这个cookie来登录 #调用Requests模块 import requests,json import random headers = { 'Referer': 'https://www.kuaidi100.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36X-Requested-With: XMLHttpRequest' } url_home = 'https://www.kuaidi100.com/' res_home = requests.get(url_home,headers=headers) headers['Cookie'] = json.dumps(requests.utils.dict_from_cookiejar(res_home.cookies)) express_com = input('请输入快递公司:') or 'zhongtong' postid = input('请输入快递单号:') or 73124161428372 url_cookies = 'https://www.kuaidi100.com/globalauto.do' params = { 'type': express_com, 'postid': postid, 'temp': random.random(), 'phone': '' } url = 'https://www.kuaidi100.com/query' res = requests.get(url,headers=headers,params=params) #print(res.status_code) js = res.json() for s in js['data']: context = s['context'] ftime = s['ftime'] print(ftime,' ',context)
测试证明,这个temp使用固定值也可以。
我今天也遇到这问题了。我找到了JS,是楼上说的随机数。但是我用java产生的随机数去查询,还是不准确。返回的物流信息是错误的,不知道楼主现在怎么样了?
第一次获取页面,取得temp 值。 循环: 邮件号码和 temp 值 查询 获取邮件轨迹及更新temp值。 应该是这样吧?
37,738
社区成员
34,210
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







 这个问题,看看怎么解决吧!
这个问题,看看怎么解决吧!



