社区
Hadoop生态社区
帖子详情
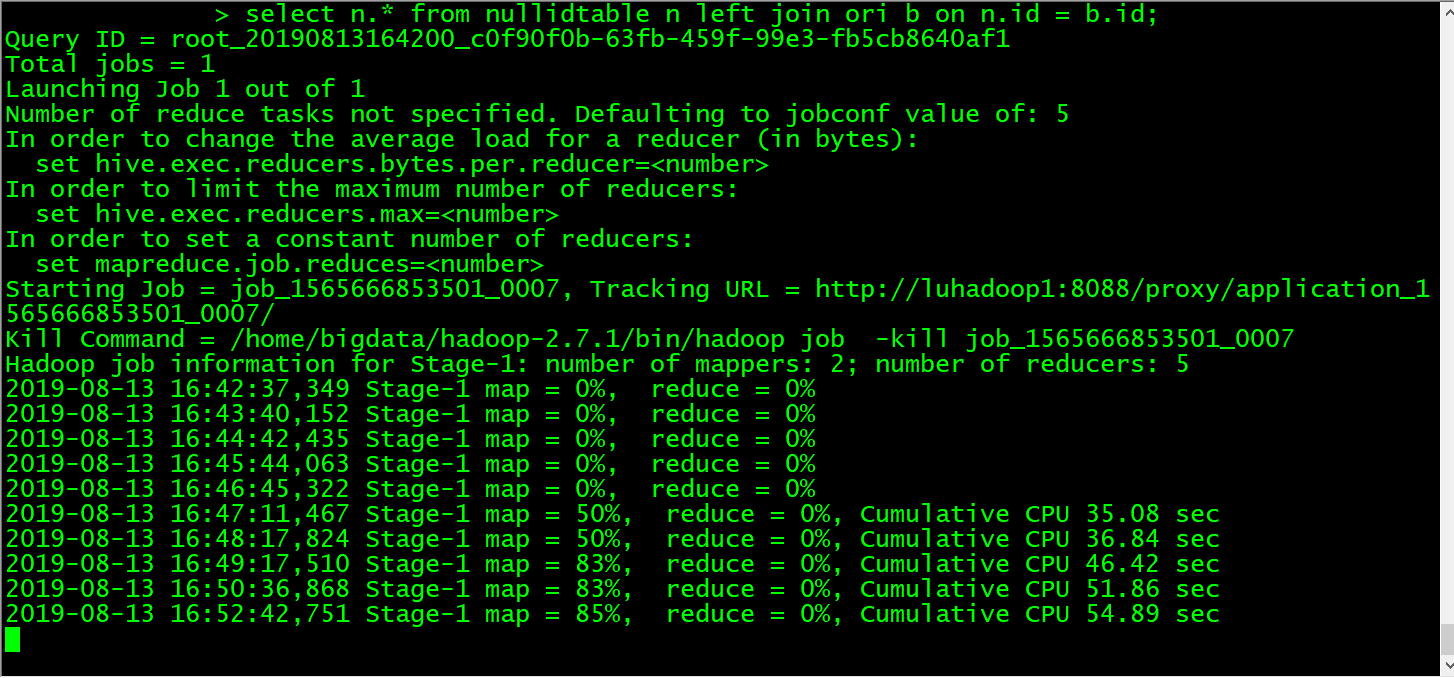
mpreduce插入运行超级慢,有没有什么办法能解决了?
1 KB
2019-08-13 04:56:23
...全文
357
5
打赏
收藏
mpreduce插入运行超级慢,有没有什么办法能解决了?
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
小羽Jary
2019-09-20
打赏
举报
回复
为什么不用tez或在spark引擎,这样速度会快很多
乐在梦想成真
2019-09-16
打赏
举报
回复
不建议直接使用mapreduce插入hive表,这本身就有性能问题,如果你懂得原理的话。如果你想从关系型数据库把数据导入hive表中,建议先使用sqoop把关系数据库的表形成文件上传hdfs,然后,再使用hive把文件load data到hive表中。
farcicalbird
2019-09-11
打赏
举报
回复
插入什么表,和直接放到临时表里面速度一样吗
1 KB
2019-08-14
打赏
举报
回复
只有百万条数据,加载很快就完成了,insert插入就会慢的吓人,正常情况下30S左右完成,但是现在都是20分钟左右。是不是哪里出问题了。
夜无边CN
2019-08-14
打赏
举报
回复
怎么确定慢呢? 数据量大小? 什么操作?
考虑电能交互的冷热电区域多微网系统双层多场景协同优化配置(Matlab代码实现)
内容概要:本文围绕“考虑电能交互的冷热电区域多微网系统双层多场景协同优化配置”的Matlab代码实现展开,提出一种结合电能交互机制的双层优化模型,用于
解决
冷、热、电多能耦合背景下多微网系统的协同规划与
运行
问题。研究采用多场景分析方法应对可再生能源出力与负荷需求的不确定性,通过上层规划设备容量配置与下层优化多时段
运行
策略的联动,提升系统在复杂环境下的经济性、鲁棒性与能源利用效率。所提供的Matlab代码集成了建模、求解(如YALMIP+CPLEX)与结果可视化全流程,涵盖场景生成与削减、双层优化结构设计及多能流协同调度等关键技术环节,为综合能源系统优化提供了完整的算法实现与技术参考。; 适合人群:具备电力系统、综合能源系统或优化建模背景,熟悉Matlab编程与数学规划方法,正在从事相关领域科研或工程设计工作的研究生、高校研究人员及能源行业技术人员。; 使用场景及目标:①开展冷热电联供(CCHP)多微网系统的容量规划与
运行
优化研究;②支撑含分布式能源、储能及多能转换设备的综合能源系统多目标、多场景优化建模;③学习与复现双层优化、分布鲁棒优化及场景分析等先进优化方法在能源系统中的实际应用。; 阅读建议:建议结合配套文献与代码同步研读,重点理解双层模型的构建逻辑、变量耦合关系与求解技巧,关注场景生成方法与YALMIP调用细节,通过调整参数、修改目标函数等方式进行仿真实验,以深化对系统优化机理的掌握。
新闻报道toy ai and safe
新闻报道toy ai and safe
Matlab GUI 经典例子.zip【GUI设计Matlab】
Matlab GUI经典案例解析 Matlab的图形用户界面(GUI)开发是其强大功能之一,通过GUIDE工具或App Designer可以快速构建交互式界面。经典案例中通常会包含以下核心元素: 主窗口布局设计 经典案例往往采用主从式窗口结构,主窗口包含菜单栏、工具栏和核心操作区。合理的控件排布和空间利用是优秀GUI的第一要素。 回调函数实现 每个控件的功能通过回调函数完成,如按钮点击触发数据处理,滑块调节实现参数动态更新。回调函数中需要注意数据传递和全局变量的合理使用。 数据可视化展示 经典案例通常会集成绘图功能,通过axes控件实时显示数据曲线或图像处理结果,这是Matlab GUI最典型的应用场景之一。 异常处理机制 完善的GUI需要包含错误检测和处理模块,比如输入数据格式校验、计算过程异常捕获等,保证用户操作的健壮性。 文件操作集成 大多数经典案例都会涉及文件读写功能,如导入Excel数据、保存处理结果等,这是GUI实用性的重要体现。 这些经典实现方式构成了Matlab GUI开发的基础范式,掌握它们可以快速构建出功能完善的专业界面。
单相逆变器闭环逆变电路PWM模型仿真研究(Simulink仿真实现)
内容概要:本文系统研究了单相逆变器闭环控制下的PWM调制模型,基于Simulink平台构建完整的逆变电路仿真系统,涵盖主电路拓扑、闭环控制器设计、脉宽调制信号生成及输出滤波等关键环节。通过引入比例积分(PI)反馈控制策略,实现对输出电压幅值与波形的精确调节,有效抑制负载扰动带来的影响,提升系统的动态响应能力与稳态精度。仿真过程详细展示了系统建模、参数整定及性能验证的全流程,重点分析了闭环控制在改善输出正弦波质量、降低谐波畸变率方面的优势,为电力电子逆变装置的研发与优化提供了可靠的理论支撑与实践参考。; 适合人群:具备电力电子技术、自动控制原理基础知识及相关仿真经验的高校研究生、科研人员,以及从事新能源发电、不间断电源(UPS)、微电网、电动汽车等领域的工程技术人员。; 使用场景及目标:①掌握单相逆变器闭环控制系统的设计与建模方法;②深入理解PWM技术与反馈控制在逆变系统中的协同工作机制;③通过Simulink仿真平台完成系统搭建与参数调试,服务于课程设计、毕业课题、科研项目或工业产品开发中的逆变器控制算法验证。; 阅读建议:建议结合经典控制理论与电力电子变换技术同步学习,动手复现仿真模型并尝试调整PI控制器参数、载波频率等关键变量,观察其对系统稳定性与输出性能的影响,从而深化对控制机理的理解,并为进一步研究并网逆变、多电平逆变等复杂系统打下坚实基础。
测试实例使用Keras.h5模型
代码转载自:https://pan.quark.cn/s/36f2a379e44e 所讨论的核心内容涉及运用Keras所训练的`.h5`模型对实例进行检测,此任务在深度学习领域内十分普遍。`.h5`作为Keras库保存模型构造与权重的文件类型,使得训练后的模型能够被储存,并在必要时被载入以执行预测操作。在开始前,务必确认已配置好Python 3.6的环境,并安装了opencv及Keras相关库。本案例中选用的数据集是MNIST,它是一个常用于手写数字识别的标准数据集。MNIST中的图像均为28x28像素的灰度图,因此在测试个人图像时,也需将其调整为相同的图像规格。若手写数字的背景并非黑色,比如呈现白底黑字的情况,可能会对模型的识别能力产生影响,因为模型在训练阶段所适应的是黑底白字的图像。因此,在测试阶段,必须保证图像被转换为黑底白字的格式。测试代码的主要步骤包括:首先,运用`load_model`函数载入`.h5`模型文件,例如使用`model = load_model(fm_cnn_BN.h5)`进行操作。其次,通过`cv2.imread`函数读取图像,再借助`cv2.cvtColor`函数将图像从RGB色彩空间转换为灰度色彩空间。同时,要确保图像的尺寸与训练模型时的输入尺寸相匹配,一般设定为28x28像素。接着,利用`reshape`方法将图像数据调整至模型所要求的维度。对于MNIST数据集而言,这通常意味着将图像转化为一个一维数组,其形状为`(1, 1, 28, 28)`,其中1代表批次大小,其余部分则分别表示图像的通道数、宽度和高度。然后,对数据进行标准化处理,将像素值缩放到0到1的范围内,这通常通过除以255来实现。最后,运用`predict_cl...
Hadoop生态社区
20,842
社区成员
4,695
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



