各位大佬:
我是计划用python爬取今日头条的新闻存到本地,思路是1.先访问首页,获取cookie;2.将获取的cookie加入header模拟成用户的方式获取关键字的新闻列表;3.再逐条爬取新闻的内容。
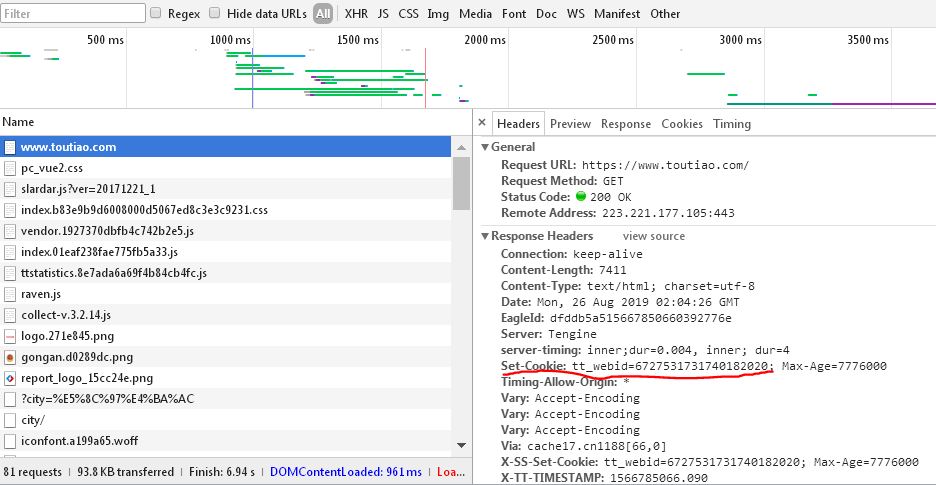
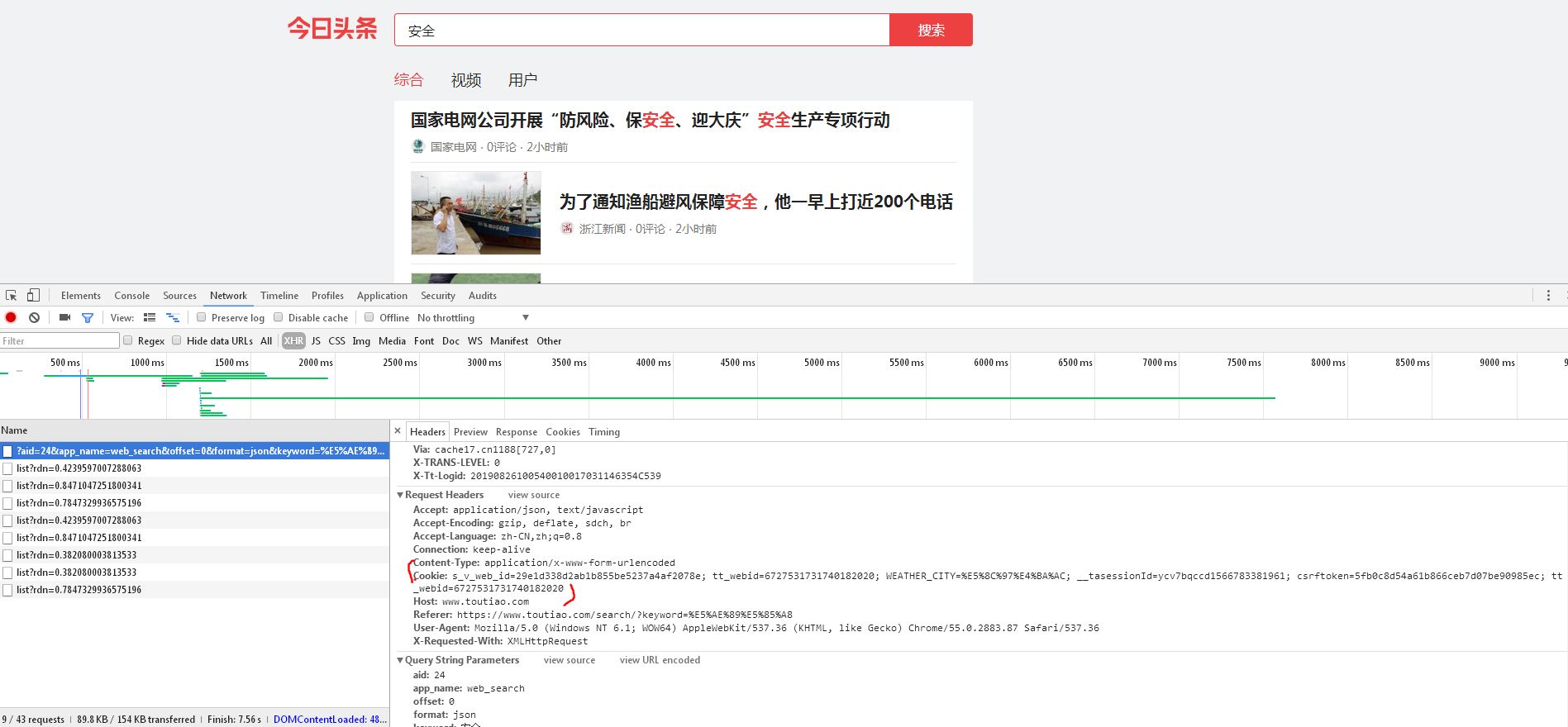
2和3已经成功了,但现在第2步的cookie(图2)是打开浏览器后从network里自己copy的cookie写死到代码里才能爬取到内容,如果用第1步获取的cookie(图1)就无法实现了。我观察了一下,第1步获取的cookie和手动从搜索得出的列表页面copy的cookie差别很大。
这个问题搞得第1步和第2步就断了....




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 ;
;
