社区
其他技术讨论专区
帖子详情
pyhton 二分K均值聚类之后怎么给每一个记录贴上聚类的标签
weixin_38059951
2016-11-25 08:13:05
用NUMPY把数据转换成矩阵,然后取出第一列(id)作为标识,然后经行聚类,最终聚类结果可以得到,但是怎么样将每一行数据在哪个类中进行记录呢?
这是二分K均值的源码,求大神教我
...全文
55
1
打赏
收藏
pyhton 二分K均值聚类之后怎么给每一个记录贴上聚类的标签
用NUMPY把数据转换成矩阵,然后取出第一列(id)作为标识,然后经行聚类,最终聚类结果可以得到,但是怎么样将每一行数据在哪个类中进行记录呢? 这是二分K均值的源码,求大神教我
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
K-means
聚类
算法原理及python具体实现
K 均值
聚类
算法 K-means Clustering Algorithm 1.1 算法步骤 步骤: 1、先定义总共有多少个类/簇【k的值可以自己指定】 2、将每个簇心,随机定在
一个
点上 3、将每
一个
簇找到其所有关联点的中心点(取每
一个
点坐标...
Python实现K-means
聚类
分析
k均值
聚类
算法(k-means clustering algorithm)是一种迭代求解的
聚类
分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的
聚类
中心,然后计算每个对象与各个种子
聚类
中心之间的距离,把每个对象分配...
Python-sklearn库 kmeans均值
聚类
import seaborn;...#这个是sklearn自带的
一个
鸢尾花数据集 X, y = iris.data, iris.target #data为训练所需的数据集,target为数据集对应的分类
标签
from sklearn.decomposition import PCA #PAC为skle
二分
k均值 Python实现
Kmeans: 优点: 简单易实现 缺点: 可能收敛于局部最小值(对初始k个
聚类
中心的选择敏感),在大规模数据集上收敛较慢 适用数据类型:数值型数据 度量
聚类
效果的指标: ...
二分
k-均值算法: 算法思想: 首先将所
python实现kmeans
聚类
_Python实现kMeans(
k均值
聚类
)
Python实现kMeans(
k均值
聚类
)运行环境
Pyhton
3numpy(科学计算包)matplotlib(画图所需,不画图可不必)计算过程st=>start: 开始e=>end: 结束op1=>operation: 读入数据op2=>operation: 随机初始化
聚类
中心...
其他技术讨论专区
476
社区成员
790,963
社区内容
发帖
与我相关
我的任务
其他技术讨论专区
其他技术讨论专区
复制链接
扫一扫
分享
社区描述
其他技术讨论专区
其他
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享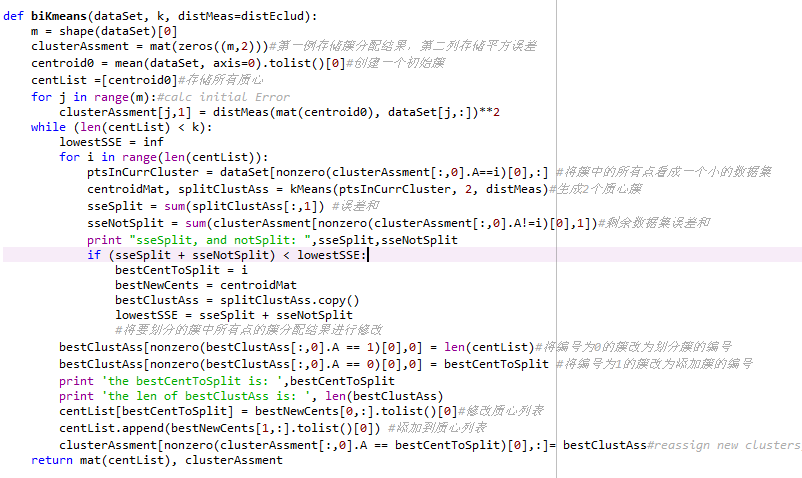 这是二分K均值的源码,求大神教我
这是二分K均值的源码,求大神教我
