社区
其他技术讨论专区
帖子详情
使用selenium获取今日头条的个人收藏页面,怎么匹配到li标签
weixin_38048397
2018-03-20 01:30:49
开发四年只会写业务代码,分布式高并发都不会还做程序员?->>>
如图所示,我去匹配这个Li的时候,点击没反应。
...全文
24
1
打赏
收藏
使用selenium获取今日头条的个人收藏页面,怎么匹配到li标签
开发四年只会写业务代码,分布式高并发都不会还做程序员?->>> 如图所示,我去匹配这个Li的时候,点击没反应。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Python爬虫实战 超多案例(百度,微博,
今日
头条
,网易,boss直聘,豆瓣爬取+全网爬取)
本课程主要给大家分享基于Python语言的网络爬虫各种工具的
使用
和实战案例,涉及的知识点requests爬虫库,Python正则表达式,xpath的
使用
,
selenium
的
使用
,进程线程协程,scrapy框架的
使用
。 本课程还有超多的实战,百度,微博,
今日
头条
,网易,boss直聘,豆瓣等网站的爬取,以及用scrapy框架爬取全网数据本教程是由IT兄弟连知名讲师姚青林老师讲解,姚老师讲课非常由代入感,很容易听懂,深受学员的喜爱! 这些实战教程肯定会对你的面试加分,让你在面试中脱颖而出!
python+
selenium
爬虫搜索
今日
头条
文章并爬取文章相关数据(点赞、评论等)
首先需要一个登录模块,由于
今日
头条
需要登陆就可以搜索,因此这里不登陆,只
获取
页面
#打开浏览器(不登陆) def login(): url = 'https://www.toutiao.com/' option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) web = Chrome(options=option) web.maximi
selenium
获取
动态网站数据
一、安装 pip install
selenium
二、下载浏览器驱动 谷歌浏览器驱动下载地址:http://npm.taobao.org/mirrors/chromedriver/ 火狐浏览器驱动下载地址:http://npm.taobao.org/mirrors/geckodriver/ 查看谷歌浏览器版本:帮助 --> 关于 Google Chrome 三、爬取
今日
头条
数据 进入到...
使用
webmagic爬取网页信息以及通过
selenium
进行
页面
元素操作
前言 本篇文章主要讲解如何
使用
webmagic技术来实现网页的爬取, 以及
使用
selenium
操作
页面
元素,实现点击、输入事件 所用技术 1.webmagic 添加需要爬取的url Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run(); 在process里面抓取符合条件...
Selenium
之学习杂记(四)
基于
今日
头条
的实战[稍微复杂]通过
Selenium
访问百度热词通过
Selenium
搜索相关热词
获取
第一条结果定位元素—— 抓取内容存储数据 通过
Selenium
访问百度热词 我们的目标网站为百度搜索风云榜。先打开百度搜索风云榜网站观察一下,我们的 为了
获取
元素,首先要进行元素定位。在网页中按F12键打开开发者工具,对实时热点这几条消息进行定位,右击并
获取
XPath。然后读者就会惊讶的发现,它的XPath都很类似,不同的只是中间一个叫作
li
的
标签
名。这就意味着,我们只需要更改
li
标签
对应的数字,就可以完成对
其他技术讨论专区
433
社区成员
791,271
社区内容
发帖
与我相关
我的任务
其他技术讨论专区
其他技术讨论专区
复制链接
扫一扫
分享
社区描述
其他技术讨论专区
其他
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享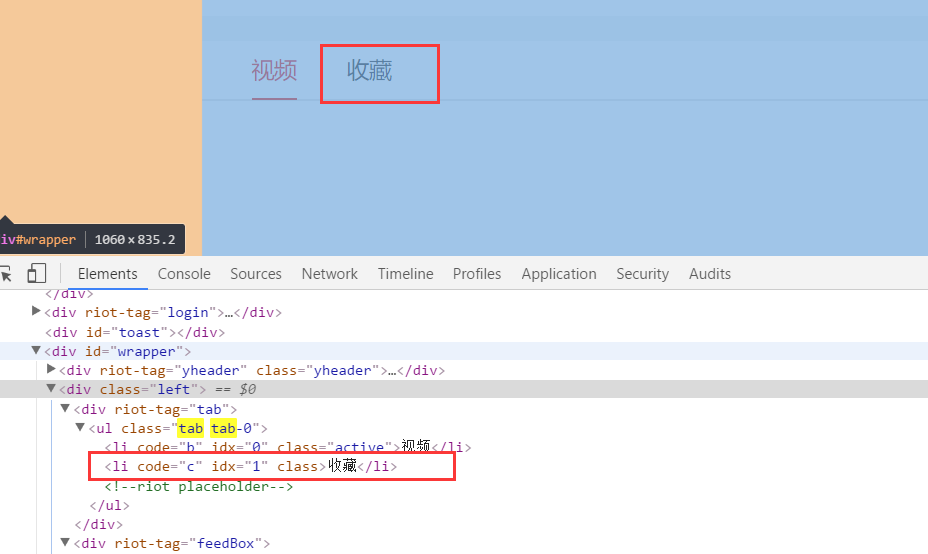 如图所示,我去匹配这个Li的时候,点击没反应。
如图所示,我去匹配这个Li的时候,点击没反应。

