<video webkit-playsinline="" playsinline="" x-webkit-airplay="" autoplay="autoplay" src="blob:http://www.izhangchu.com/d6da357a-3623-4596-9e3e-5601218cff51" style="width: 100%; height: 100%;"></video>
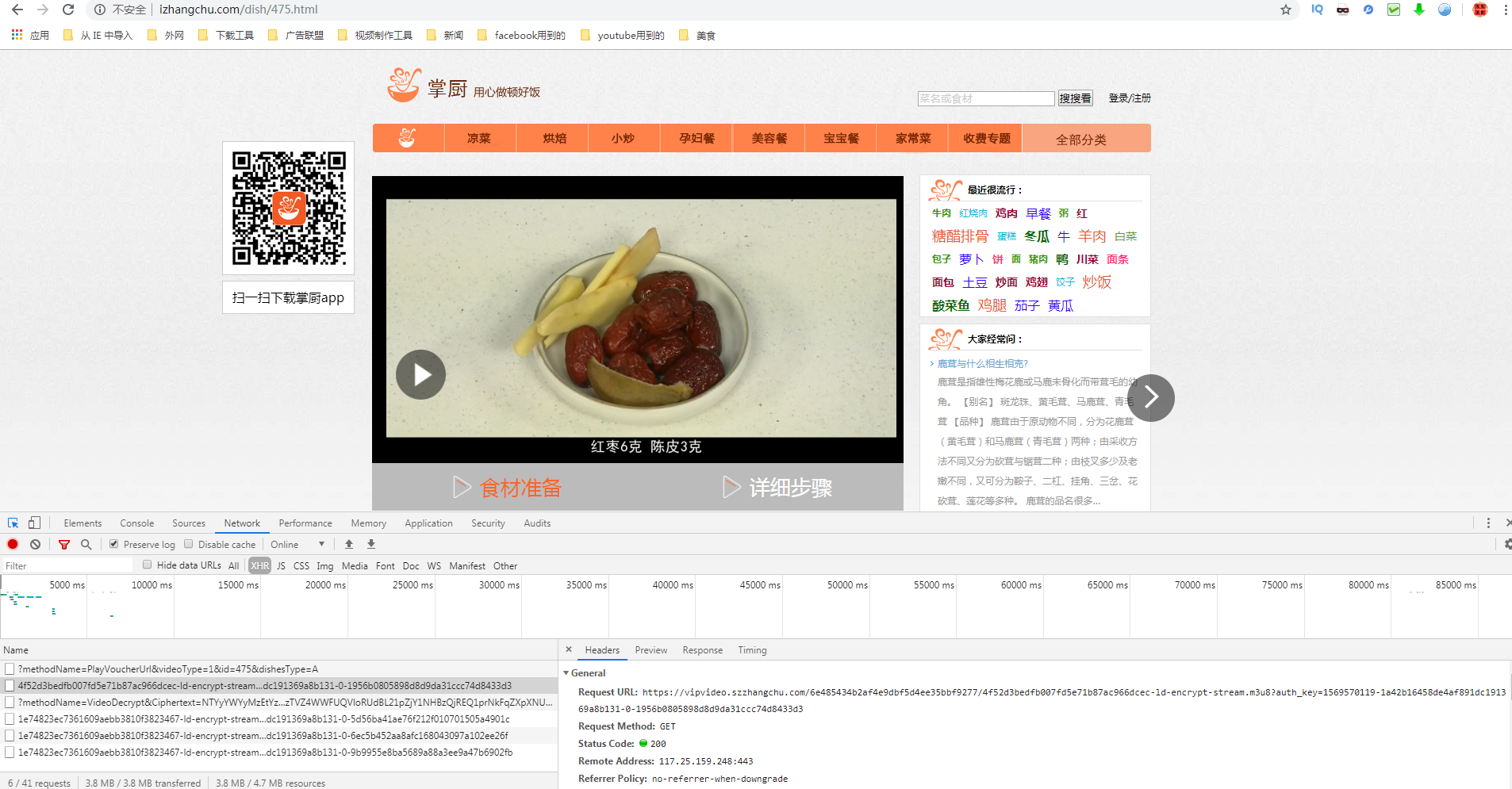
Request URL: https://vipvideo.szzhangchu.com/6e485434b2af4e9dbf5d4ee35bbf9277/4f52d3bedfb007fd5e71b87ac966dcec-ld-encrypt-stream.m3u8?auth_key=1569570119-1a42b16458de4af891dc191369a8b131-0-1956b0805898d8d9da31ccc74d8433d3
Request Method: GET
Status Code: 200
Remote Address: 117.25.159.248:443
Referrer Policy: no-referrer-when-downgrade
如何用python下载这个视频?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



