Hadoop版本:2.8.1
问题描述:在测试文件上传的时候,遇到 java.lang.ClassNotFoundException类的异常:
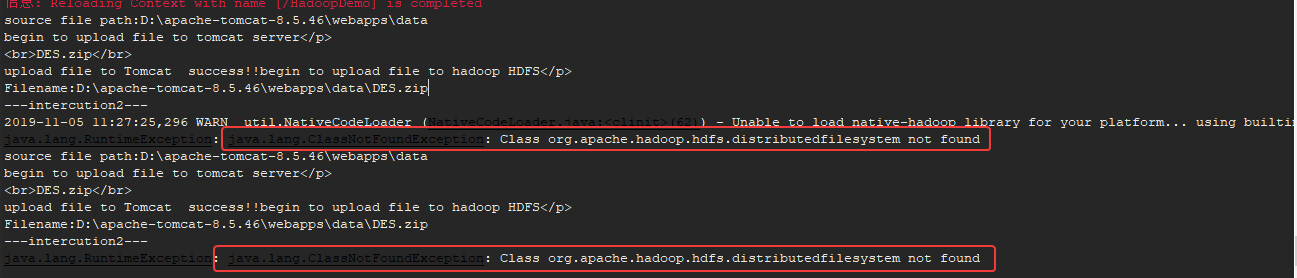
一开始以为是jar包不全,把所有hdfs文件下的jar包都丢进去了,依然报错,而且最后在hadoop-hdfs-client-2.8.1中找到了这个类
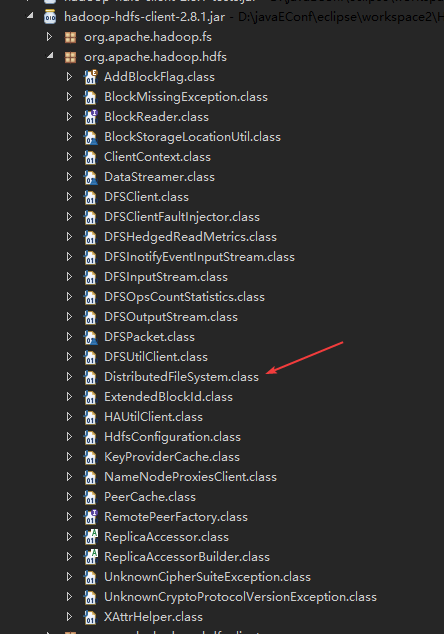
但是这里的类名是
DistributedFileSystem而命令台显示的错误是
distributedfilesystem,为什么会出现这种情况??

逐步排查发现应该是下面这句引发的错误
FileSystem fs=FileSystem.get(URI.create(hdfsPath),conf);
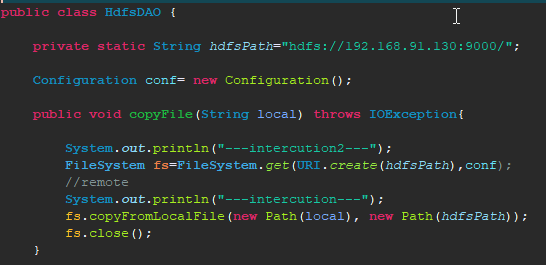
查了相关的Filesystem.get()的API文档,没有看到哪里需要distributedfilesystem
麻烦大神来看看,卡在这里几天了



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



