社区
高性能WEB开发
帖子详情
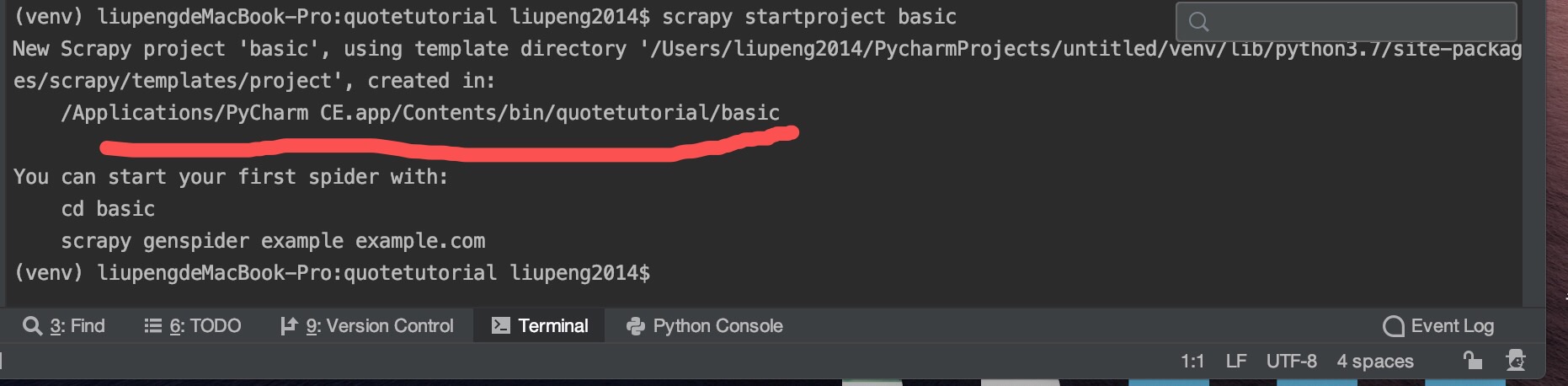
scrapy创建的文件夹能否改变默认路径?
weixin_45855539
2019-11-08 06:10:33
我用的pycharm的终端,用scrapy startproject 后默认建立的文件夹路径在pycharm的系统文件夹一下,非常难找到,不知道从哪里能改变这个路径?
...全文
126
回复
打赏
收藏
scrapy创建的文件夹能否改变默认路径?
我用的pycharm的终端,用scrapy startproject 后默认建立的文件夹路径在pycharm的系统文件夹一下,非常难找到,不知道从哪里能改变这个路径?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Python爬虫
Scrapy
框架基础与实战项目案例
学习Python爬虫,怎能少了
Scrapy
框架?
Scrapy
框架是爬虫集大成者,让你享受框架带来的种种流畅和便利。本课程讲解爬虫相关基础,通过多个实际案例,深入浅出吃透
Scrapy
框架的架构原理及具体使用方法。学完本课程,你也就上手了
Scrapy
框架,能独立使用
Scrapy
框架爬取多数网站内容以及下载文件。----------------------------------------------------------------scarpy是分布式爬虫框架。——实现爬取网站数据、提取结构性数据而编写的应用框架,用途广泛。 框架的作用?相当于建高楼大厦,已经做好了框架结构,只需要根据具体需求和目标砌墙和搞装修就行啦。使用scarpy,就已经有了爬虫框架;只需要根据具体需求和目标,做好少部分模块,就可以很方便爬取到数据资源。
Scrapy
源码剖析(三)
Scrapy
有哪些核心组件?
微信搜索关注「水滴与银弹」公众号,第一时间获取优质技术干货。7年资深后端研发,用简单的方式把技术讲清楚。 在上一篇文章:
Scrapy
源码剖析(二)
Scrapy
是如何运行起来的?,我们主要剖析了
Scrapy
是如何运行起来的核心逻辑,也就是在真正执行抓取任务之前,
Scrapy
都做了哪些工作。 这篇文章,我们就来进一步剖析一下,
Scrapy
有哪些核心组件?以及它们主要负责了哪些工作?这些组件为了完成这些功能,内部又是如何实现的。 爬虫类 我们接着上一篇结束的地方开始讲起。上次讲到
Scrapy
运.
scrapy
框架Images Pipeline下载图片(重写方法来指定下载位置)
使用
scrapy
框架下载图片 先介绍一下os模块: import os即可 使用os.path.dirname (__ file__) 可以查看当前文件所在的目录,以如下目录为例: 使用os.path.dirname(__ file__)得到的是第二个bmw(即蓝色框下面的那个)目录,假如我们想要在第一个bmw下面
创建
一个images
文件夹
,应该怎么做呢? 所以我们使用os.path.dirname(os.path.dirname(file))语句,如此得到的就是第二个bmw所在的目录了(也就是第一个
爬虫框架
Scrapy
详解
Scrapy
是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy
用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy
是一个框架,可以根据需求进行定制。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。...
Scrapy
框架知识手册 - 从零到一
Scrapy
框架一、初识
Scrapy
1、
Scrapy
简介2、网络爬虫原理3、网络爬虫的基本流程二、
Scrapy
安装与
创建
1、安装2、查看命令3、主要命令三、
Scrapy
简单实现1、项目
创建
2、
创建
爬虫3、更改robot协议4、分析页面5、编写spider6、解析页面7、运行爬虫四、
Scrapy
框架结构1、
Scrapy
结构2、
Scrapy
原理(数据流动)3、
Scrapy
各个组件的介绍五、spiders文件之spider.Spider1、Spider1.1、name1.1、allowed_domains1.2、
高性能WEB开发
25,985
社区成员
4,366
社区内容
发帖
与我相关
我的任务
高性能WEB开发
高性能WEB开发
复制链接
扫一扫
分享
社区描述
高性能WEB开发
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
