

62,621
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

package com.sxz.timecontroal;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.zip.GZIPInputStream;
import org.apache.http.Header;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
public class CheckTimeWithNet {
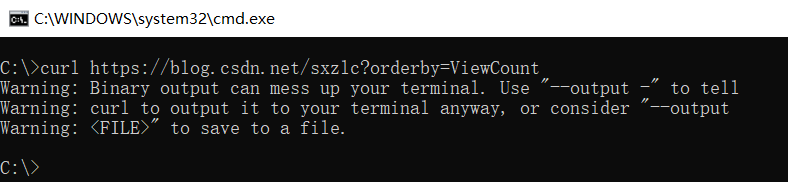
static final String LOGINURL = "https://blog.csdn.net/sxzlc?orderby=ViewCount";
//static final String LOGINURL = "https://blog.csdn.net/sxzlc/article/list/2?orderby=ViewCount";
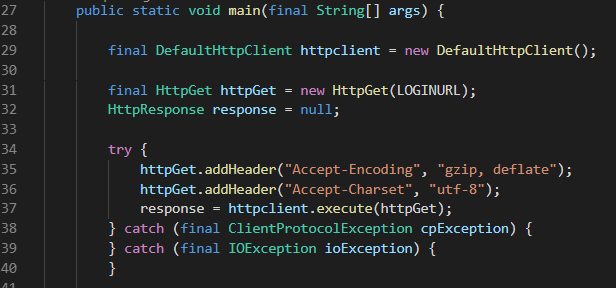
public static void main(final String[] args) {
final DefaultHttpClient httpclient = new DefaultHttpClient();
final HttpGet httpGet = new HttpGet(LOGINURL);
HttpResponse response = null;
try {
//httpGet.addHeader("Accept-Encoding", "gzip, deflate");
httpGet.addHeader("Accept-Charset", "utf-8");
response = httpclient.execute(httpGet);
} catch (final ClientProtocolException cpException) {
} catch (final IOException ioException) {
}
// verify response is HTTP OK
final int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != HttpStatus.SC_OK) {
System.out.println("Error authenticating to Force.com: "+statusCode);
return;
}
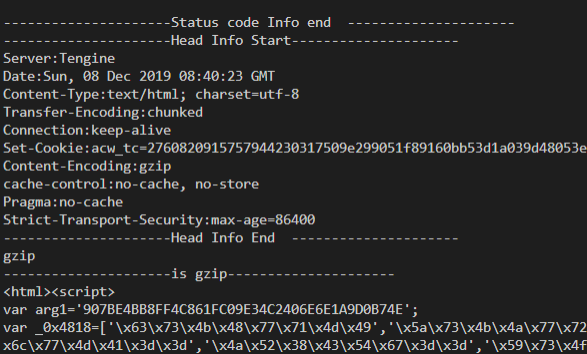
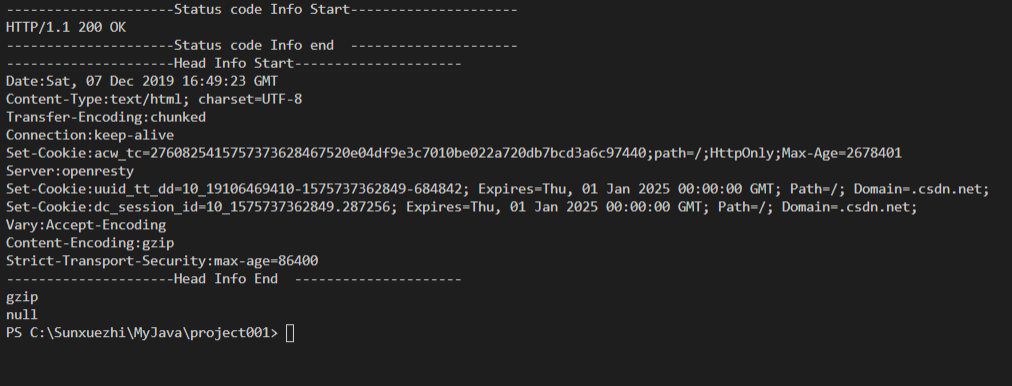
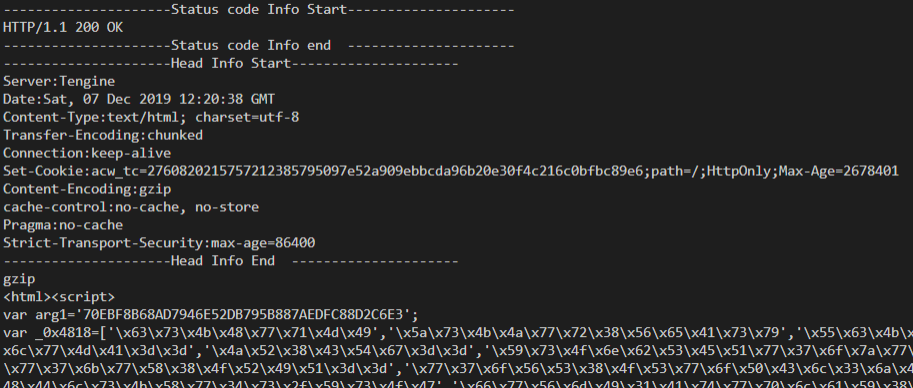
System.out.println("---------------------Status code Info Start---------------------");
System.out.println(response.getStatusLine());
System.out.println("---------------------Status code Info end ---------------------");
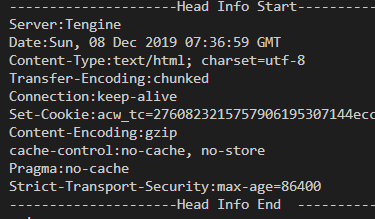
System.out.println("---------------------Head Info Start---------------------");
final Header[] hs = response.getAllHeaders();
for(final Header h:hs){
System.out.println(h.getName() + ":" + h.getValue());
}
System.out.println("---------------------Head Info End ---------------------");
String getResult = null;
try {
// response.setEntity(new GzipDecompressingEntity(response.getEntity()));
// getResult = EntityUtils.toString(response.getEntity(),"UTF-8");
getResult = getStringFromResponseUzip(response);
} catch (final Exception ioException) {
// Handle system IO exception
}
System.out.println(getResult);
}
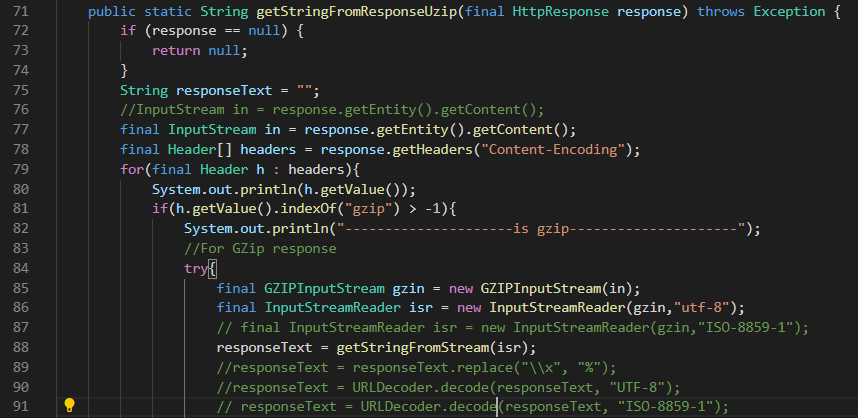
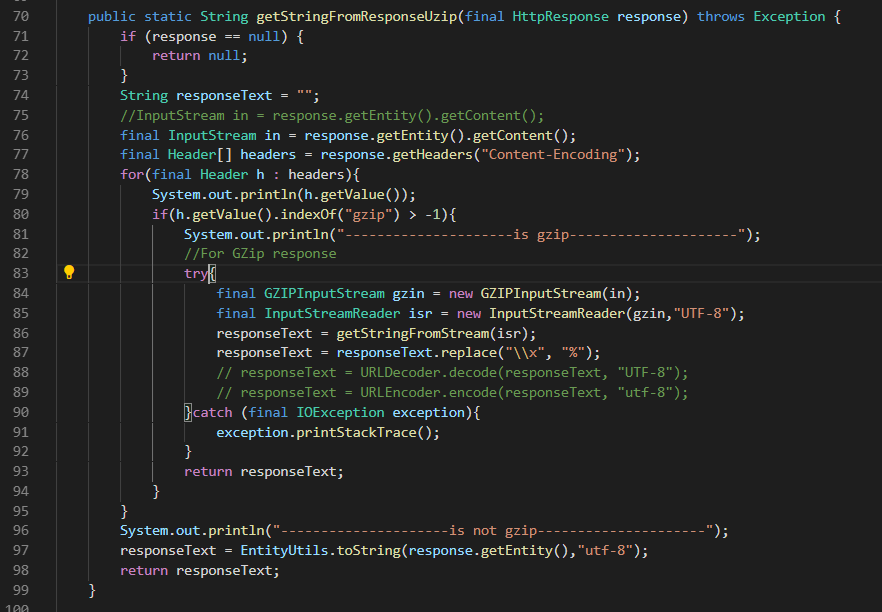
public static String getStringFromResponseUzip(final HttpResponse response) throws Exception {
if (response == null) {
return null;
}
String responseText = "";
//InputStream in = response.getEntity().getContent();
final InputStream in = response.getEntity().getContent();
final Header[] headers = response.getHeaders("Content-Encoding");
for(final Header h : headers){
System.out.println(h.getValue());
if(h.getValue().indexOf("gzip") > -1){
System.out.println("---------------------is gzip---------------------");
//For GZip response
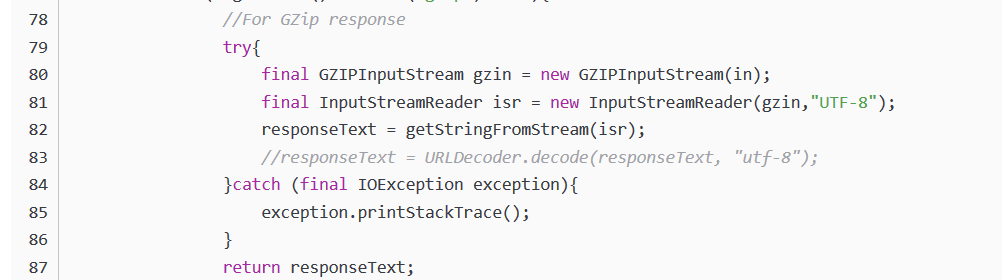
try{
final GZIPInputStream gzin = new GZIPInputStream(in);
final InputStreamReader isr = new InputStreamReader(gzin,"utf-8");
// final InputStreamReader isr = new InputStreamReader(gzin,"ISO-8859-1");
responseText = getStringFromStream(isr);
responseText = responseText.replace("\\x", "%");
//responseText = URLDecoder.decode(responseText, "UTF-8");
// responseText = URLDecoder.decode(responseText, "ISO-8859-1");
// responseText = URLEncoder.encode(responseText, "utf-8");
}catch (final IOException exception){
exception.printStackTrace();
}
return responseText;
}
}
System.out.println("---------------------is not gzip---------------------");
responseText = EntityUtils.toString(response.getEntity(),"utf-8");
return responseText;
}
public static String getStringFromStream(final InputStreamReader isr) throws Exception{
final BufferedReader br = new BufferedReader(isr);
final StringBuilder sb = new StringBuilder();
String tmp;
while((tmp = br.readLine())!=null){
sb.append(tmp);
sb.append("\r\n");
}
br.close();
isr.close();
return sb.toString();
}
}