


37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享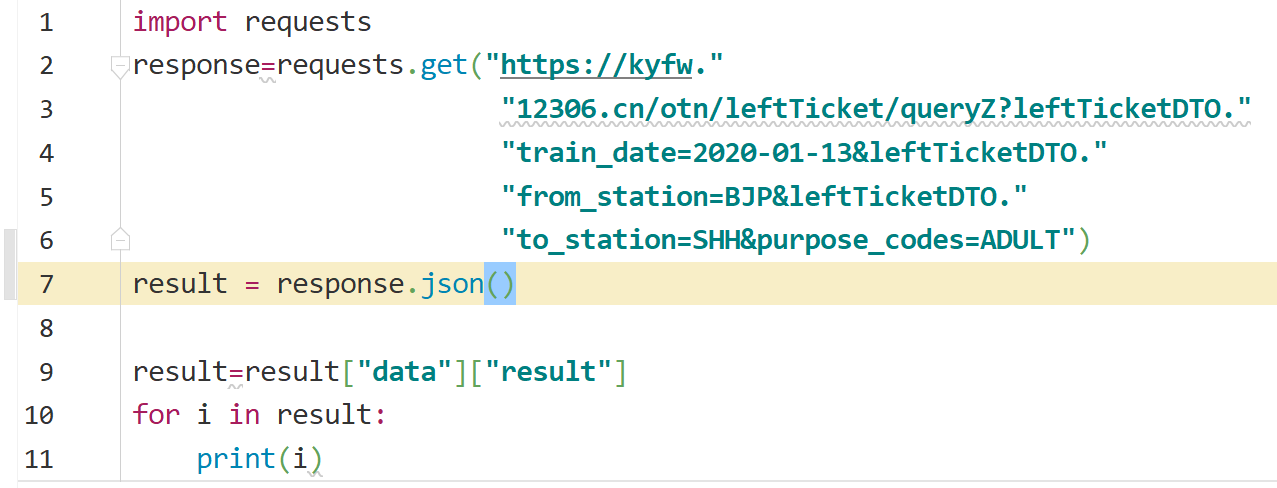


url = ("https://kyfw.12306.cn/otn/leftTicket/query?"
"leftTicketDTO.train_date={}&"
"leftTicketDTO.from_station={}&"
"leftTicketDTO.to_station={}&"
"purpose_codes=ADULT").format(date, from_stion, to_stion)
headers = {
# Cookie 的值自行替换一下,可以通过打开浏览器开发者模式复制过来
"Cookie": "_uab_collina=160395250285657341202147; JSESSIONID=7C56E896658518A4E5BF99889839D00C; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; BIGipServerotn=1725497610.50210.0000; RAIL_EXPIRATION=1604632917257; RAIL_DEVICEID=DeBrCMshZyD9JIK2yazJV4op0oxRXXKpeio_Y27U75ZkWKFwOd6Q_i2JRVBJeN3Q9qQ7ybyTw4Vv3ImAEwdTAAh8XLXL6WGn3irR65rZyYeWtvToLkq8oVAprmAw6OPgPnqI9a9ItALNr0kFjzDkncjjGPINbqfa; BIGipServerpassport=770179338.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromDate=2020-11-02; _jc_save_toDate=2020-11-01",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
requests.packages.urllib3.disable_warnings() # 屏蔽 “InsecureRequestWarning” 警告
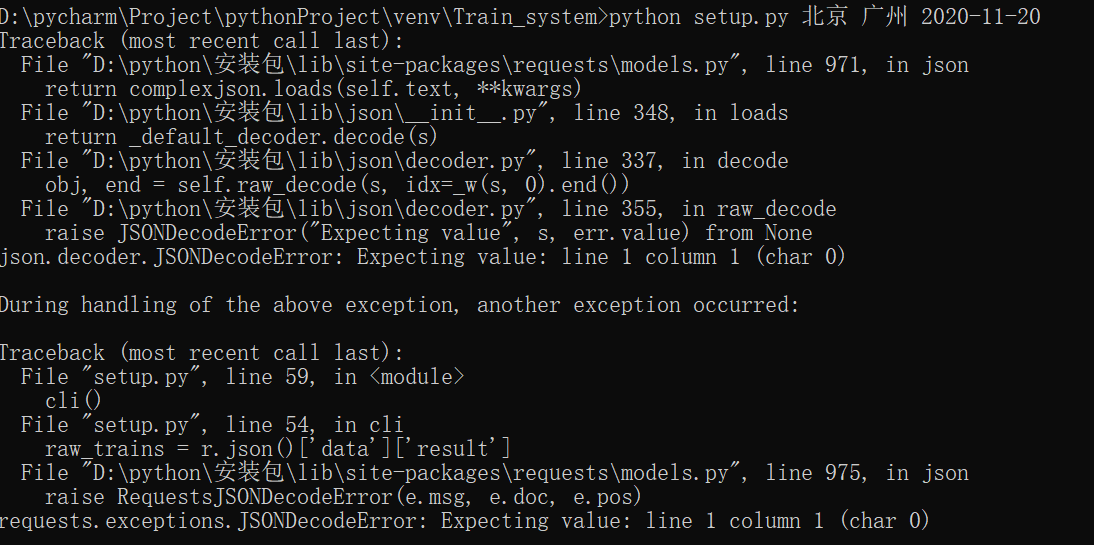
r = requests.get(url, headers=headers, verify=False) # 通过 requests 模块获取页面信息,verify=False 参数表示不进行证书验证
r = r.content.decode(encoding='utf-8')
raw_trains = r.json()['data']['result']
print(raw_trains)
大哥么咋改啊





 可是,,那个视频里的真的打开了
可是,,那个视频里的真的打开了
import requests, random
from ulits import config
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2020-01-13&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=CQW&purpose_codes=ADULT'
headers = {
'User-Agent': random.choice(config.USER_AGENT_POOL),
'Cookie': 'JSESSIONID=B709F9775E72BDED99B2EEBB8CA7FBB9; BIGipServerotn=1910046986.24610.0000; RAIL_EXPIRATION=1579188884851; RAIL_DEVIC'
}
res = requests.get(url=url, headers=headers)
res_info = res.json()
print(res_info)


res_html = res.content.decode(encoding='utf-8')
# 或者
res_html - res.text
print(res_html)

