

37,744
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
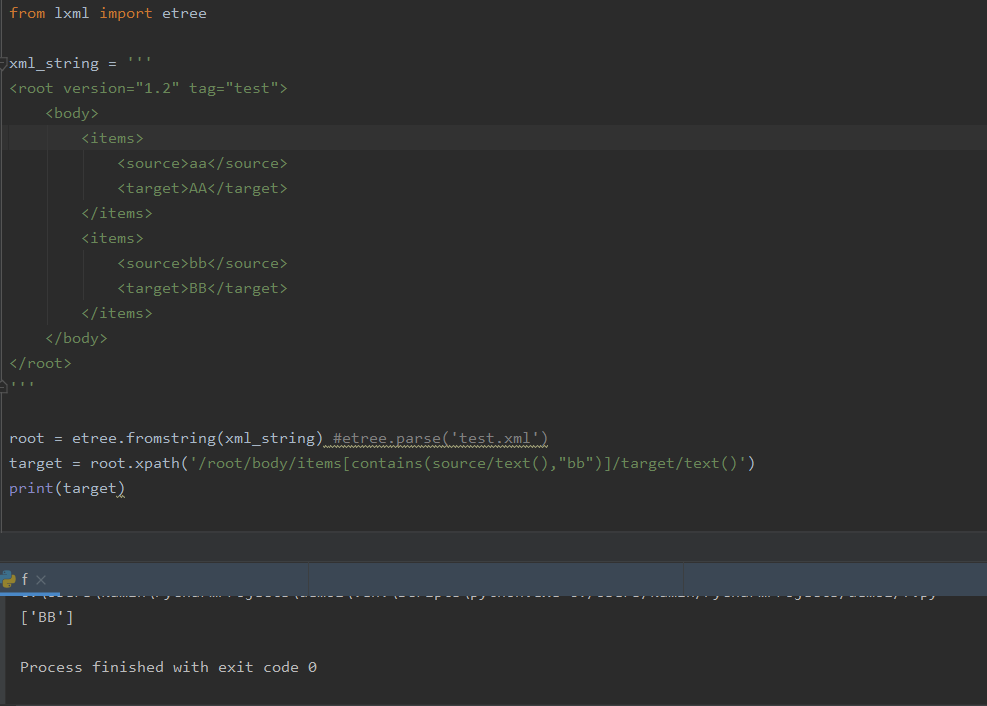

root = etree.fromstring(xml_string) #etree.parse('test.xml')
target = root.xpath('/root/body/items[contains(source/text(),"bb")]/target/text()')
print(target)
root = etree.fromstring(xml_string) #etree.parse('test.xml')
target = [''.join(e.xpath('target/text()')) for e in root.xpath('/root/body/items') if ''.join(e.xpath('source/text()'))=='bb']
print(target)

