


12,165
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
using System;
using System.Net;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace PicDownload
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
GetData();
}
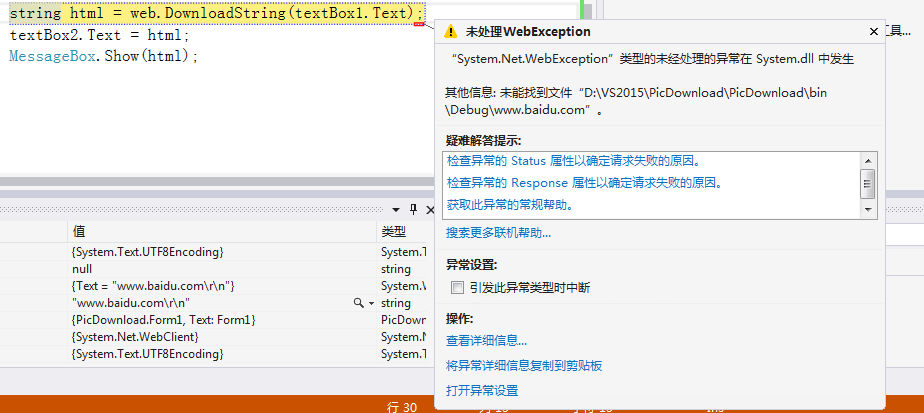
public void GetData()
{
WebClient web = new WebClient();
web.Encoding = Encoding.UTF8;
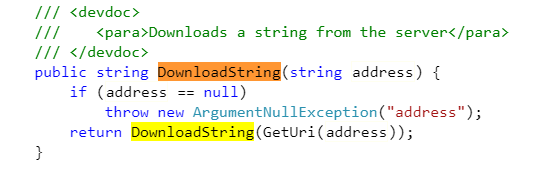
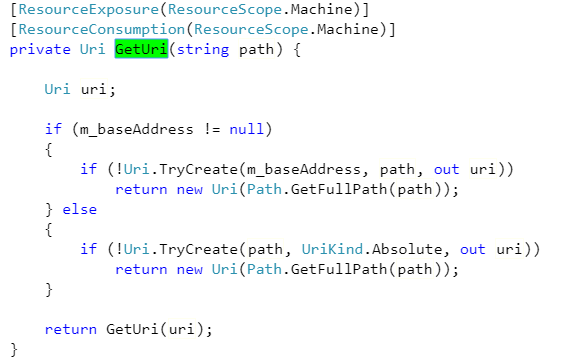
string html = web.DownloadString(textBox1.Text);
textBox2.Text = html;
MessageBox.Show(html);
}
}
}