



37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享import requests #Get web data the resource
from lxml import etree
import re
#keyword = input("Job Search:")
#page = input("Page Search:")
keyword = "veeva"
next_url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html?'.format(keyword,1)
respond = requests.get(next_url)
respond.encoding = respond.apparent_encoding
respond1 = respond.text
#print(respond1)
html = etree.HTML(respond1)
test1 = html.xpath('//*[@id="resultList"]/div[55]/div/div/div/span[1]/text()')[0]
test2 = re.findall(r"\d+\.?\d*", test1)[0]
# return test2
salary = html.xpath('//div[@class="el"]/span[@class="t4"]/text()')
print (salary)


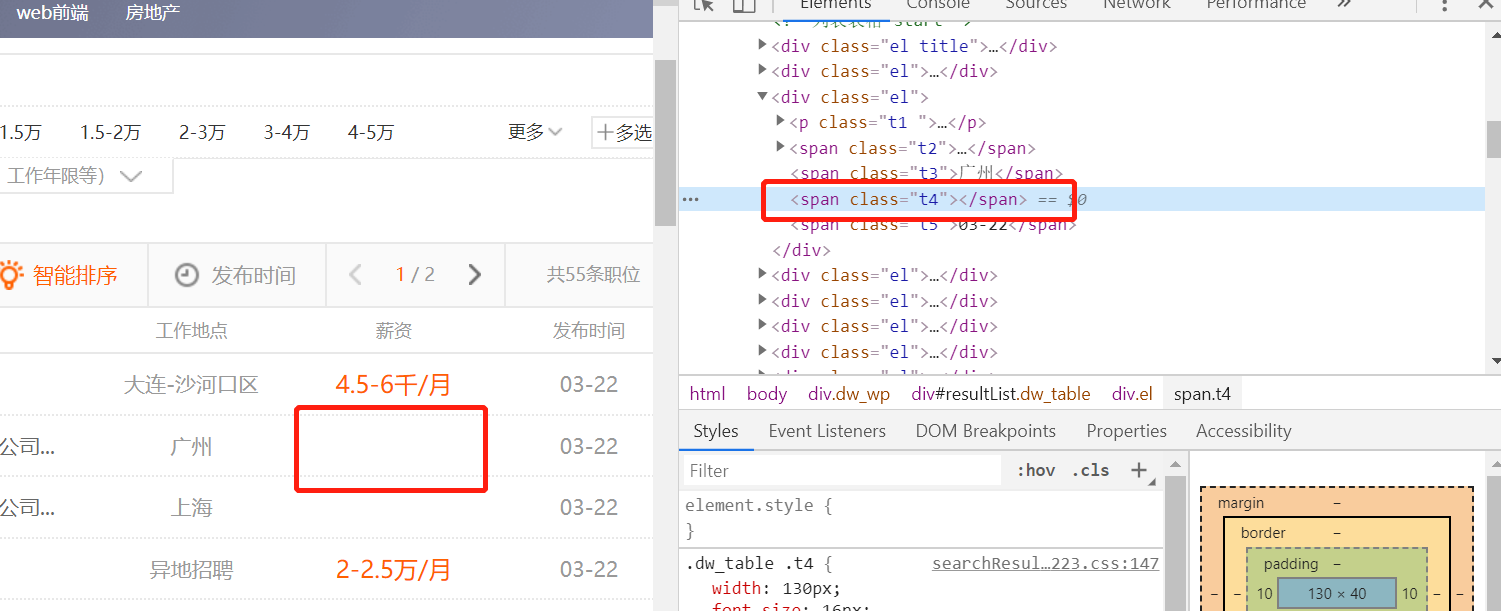

salary = [x.text for x in html.xpath('//div[@class="el"]/span[@class="t4"]')]


