

20,842
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
[root@flink102 kafka-2.11]# jps
15459 QuorumPeerMain
21466 Kafka
[root@flink102 kafka-2.11]# bin/kafka-topics.sh --zookeeper flink102:2181 --list
ct
[root@flink102 kafka-2.11]# bin/kafka-console-consumer.sh --zookeeper flink102:2181 --from-beginning --topic ct
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[root@flink102 ~]# cd /opt/workProject/
[root@flink102 workProject]# ll
total 32
-rw-r--r-- 1 root root 4312 Mar 27 15:10 call.log
-rw-r--r-- 1 root root 543 Mar 24 12:26 contact.log
-rw-r--r-- 1 root root 14155 Mar 24 12:53 ct-producer.jar
-rw-r--r-- 1 root root 683 Mar 27 14:37 flume-kafka.conf
drwxr-xr-x 2 root root 24 Mar 25 11:11 log
[root@flink102 workProject]# vim flume-kafka.conf
//添加配置参数:
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# # source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/workProject/call.log
a1.sources.r1.shell = /bin/bash -c
# # sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers =flink102:9092
a1.sinks.k1.kafka.topic = ct
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# # channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
# # bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[root@flink102 workProject]# tail -f call.log
15884588694 19154926260 20180721043739 1172
16574556259 19154926260 20180311120306 0942
15280214634 15647679901 20180904154615 0234
16160892861 14171709460 20181223154548 1720
15244749863 19342117869 20180404160230 2565
15647679901 14171709460 20180801213806 0758
15884588694 14397114174 20180222050955 0458
19154926260 16569963779 20180715235743 1489
14171709460 19602240179 20181120075855 2488
19683537146 16574556259 20180724031723 0652
[root@flink102 ~]# cd /usr/hadoop/module/flume/flume-1.7.0/
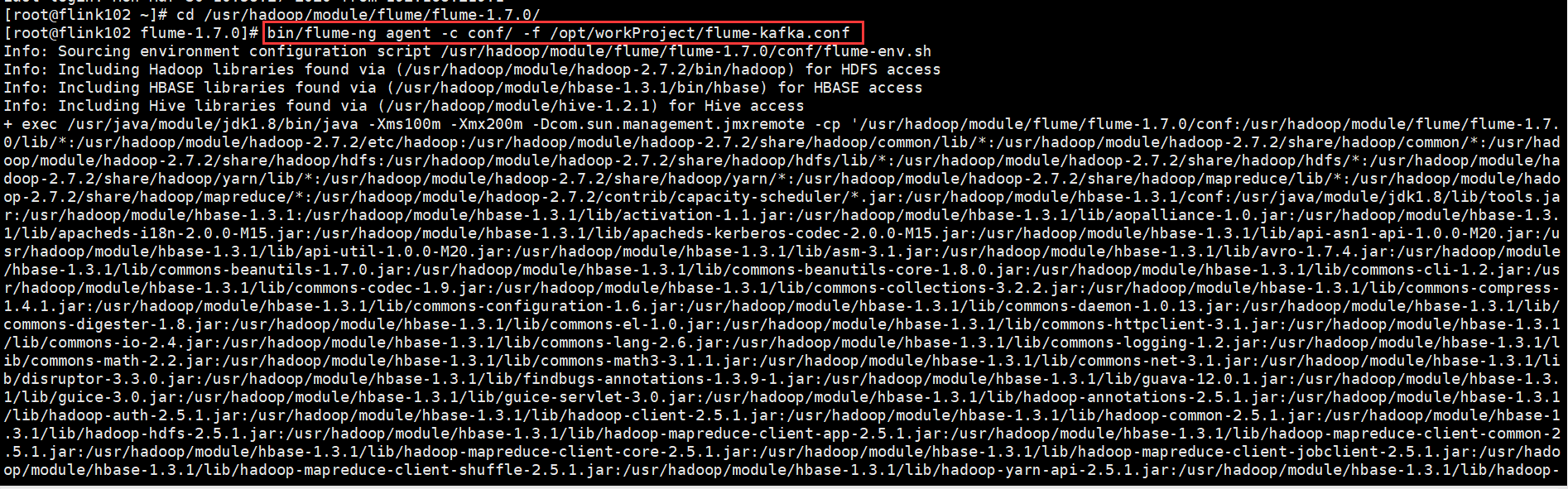
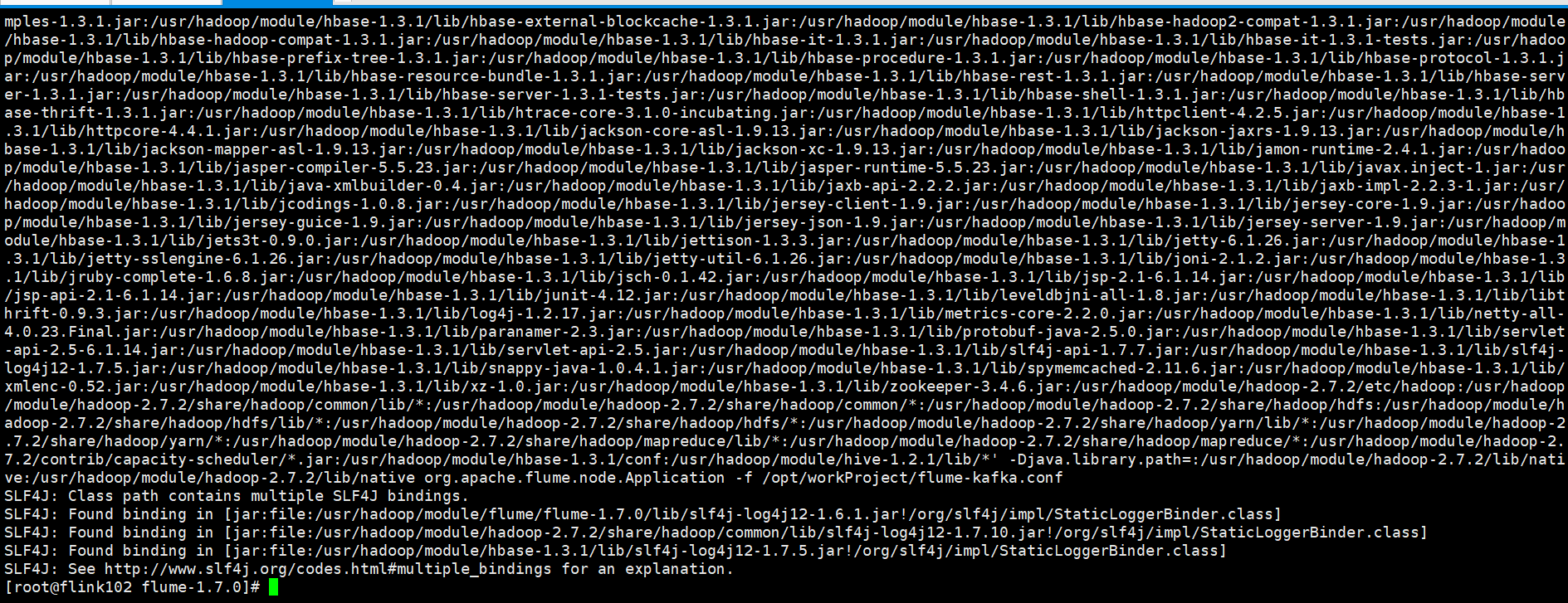
[root@flink102 flume-1.7.0]# bin/flume-ng agent -c conf/ -f /opt/workProject/flume-kafka.conf

[root@flink102 kafka-2.11]# bin/kafka-console-consumer.sh --zookeeper flink102:2181 --from-beginning --topic ct
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[2020-03-30 10:59:11,139] INFO [Group Metadata Manager on Broker 3]: Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
30 Mar 2020 11:15:33,808 ERROR [main] (org.apache.flume.node.Application.main:348) - A fatal error occurred while running. Exception follows.
org.apache.commons.cli.MissingOptionException: Missing required option: n
at org.apache.commons.cli.Parser.checkRequiredOptions(Parser.java:299)
at org.apache.commons.cli.Parser.parse(Parser.java:231)
at org.apache.commons.cli.Parser.parse(Parser.java:85)
at org.apache.flume.node.Application.main(Application.java:263)

你好 解决了吗 我也遇到了同样的问题 无法正常消费

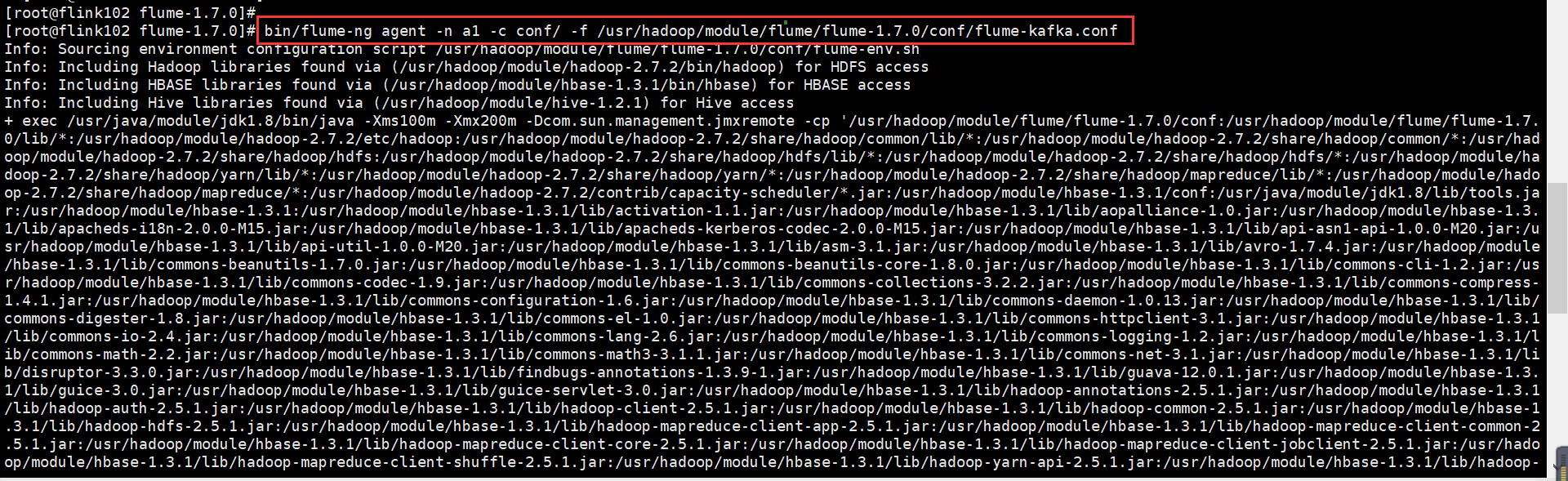
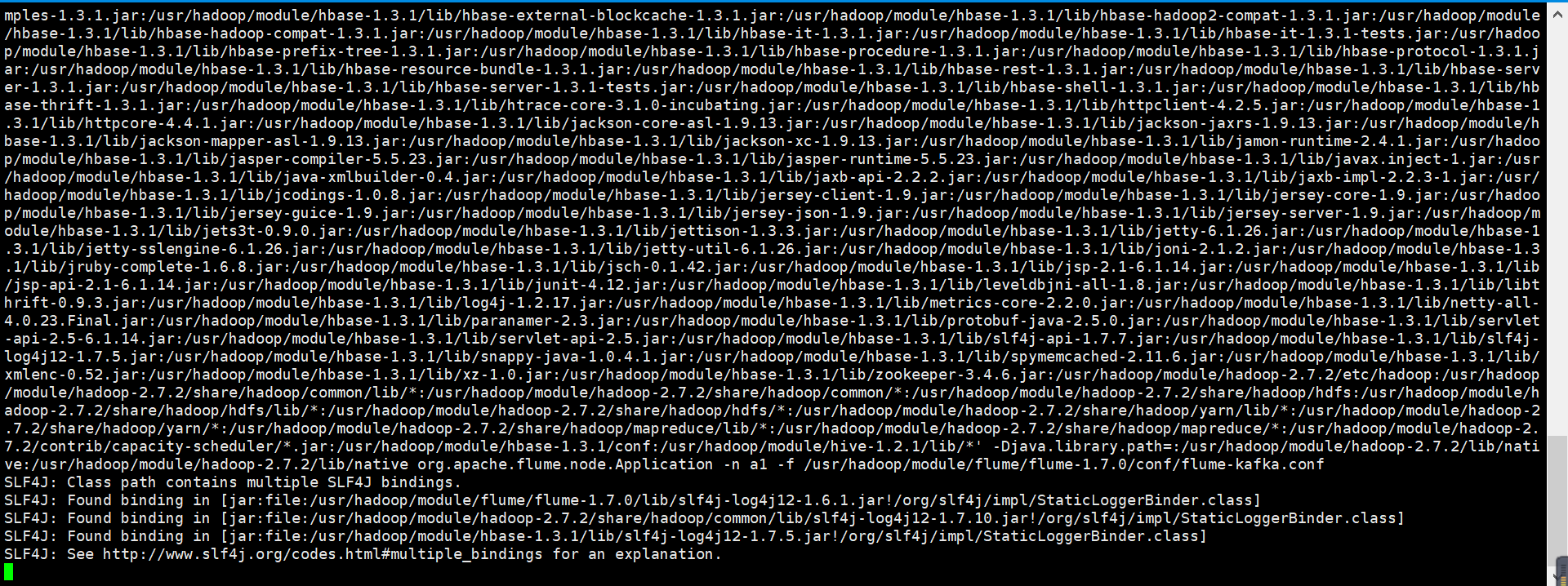
[root@flink102 flume-1.7.0]# bin/flume-ng agent -n a1 -c conf/ -f /usr/hadoop/module/flume/flume-1.7.0/conf/flume-kafka.conf
 kafka消费者,好像还是收不到
kafka消费者,好像还是收不到
[root@flink102 kafka-2.11]# bin/kafka-console-consumer.sh --zookeeper flink102:2181 --topic ct
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].


# # source
a1.sources.r1.type = exec
a1.sources.r1.command =tail -f -c +0 /opt/workProject/call.log
a1.sources.r1.shell = /bin/bash -c
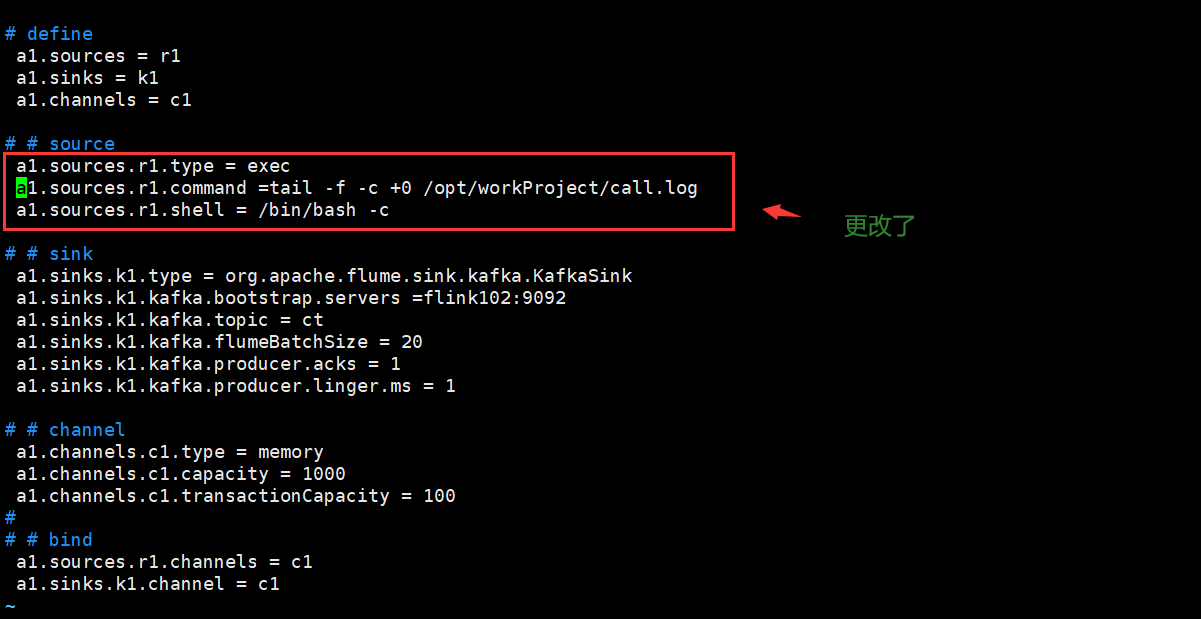 之后,我再重新启动kafka的消费者
之后,我再重新启动kafka的消费者
[root@flink102 kafka-2.11]# bin/kafka-console-consumer.sh --zookeeper flink102:2181 --topic ct
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[root@flink102 flume-1.7.0]# bin/flume-ng agent -c conf/ a1 -f /usr/hadoop/module/flume/flume-1.7.0/conf/flume-kafka.conf
 最后,在kafka消费者,还是无法接收数据
最后,在kafka消费者,还是无法接收数据
[root@flink102 kafka-2.11]# bin/kafka-console-consumer.sh --zookeeper flink102:2181 --topic ct
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[2020-03-30 16:30:28,065] INFO [Group Metadata Manager on Broker 1]: Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
[root@flink102 flume-1.7.0]# tail -f logs/flume.log
at org.apache.commons.cli.Parser.checkRequiredOptions(Parser.java:299)
at org.apache.commons.cli.Parser.parse(Parser.java:231)
at org.apache.commons.cli.Parser.parse(Parser.java:85)
at org.apache.flume.node.Application.main(Application.java:263)
30 Mar 2020 16:38:04,434 ERROR [main] (org.apache.flume.node.Application.main:348) - A fatal error occurred while running. Exception follows.
org.apache.commons.cli.MissingOptionException: Missing required option: n
at org.apache.commons.cli.Parser.checkRequiredOptions(Parser.java:299)
at org.apache.commons.cli.Parser.parse(Parser.java:231)
at org.apache.commons.cli.Parser.parse(Parser.java:85)
at org.apache.flume.node.Application.main(Application.java:263)
# # source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/workProject/call.log
a1.sources.r1.shell = /bin/bash -c


