小白求助

第一种:
scrapy通过代理爬取数据,当某一个代理出现延迟时,程序会卡住,直到请求时间达到 DOWNLOAD_TIMEOUT这个数值,才会报错释放线程,在这个等待的过程中什么事都没做,如果代理质量不高的话整体爬取的时间就会很慢。
但是如果是用c#或者java做多线程爬取则不会出现这个问题,线程之间是互不影响
速度:一秒两条以上
配置:
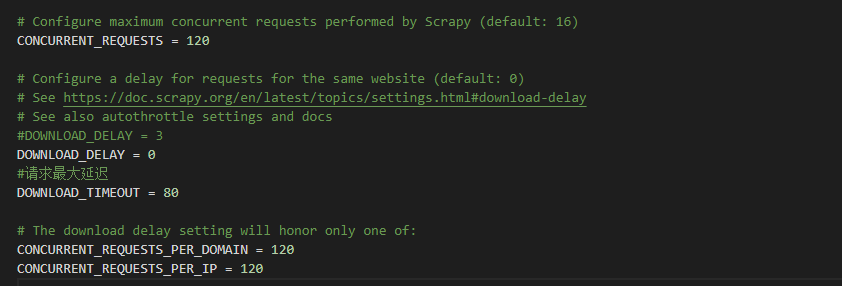
第二种:
代理检测
如果在请求指定链接之前,先采取代理检测操作,就不会出现上面那个问题,但是又有一个新的问题。
如果这个代理是可用的,那么代理检测操作又显得多余,而且整体速度是要比不检测时要慢的
速度:一秒一条
速度上比较肯定是第一种比较好的,第一种有没有什么解决方案呢?
或者有没有更好的方法?求大佬给个建议



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

