37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
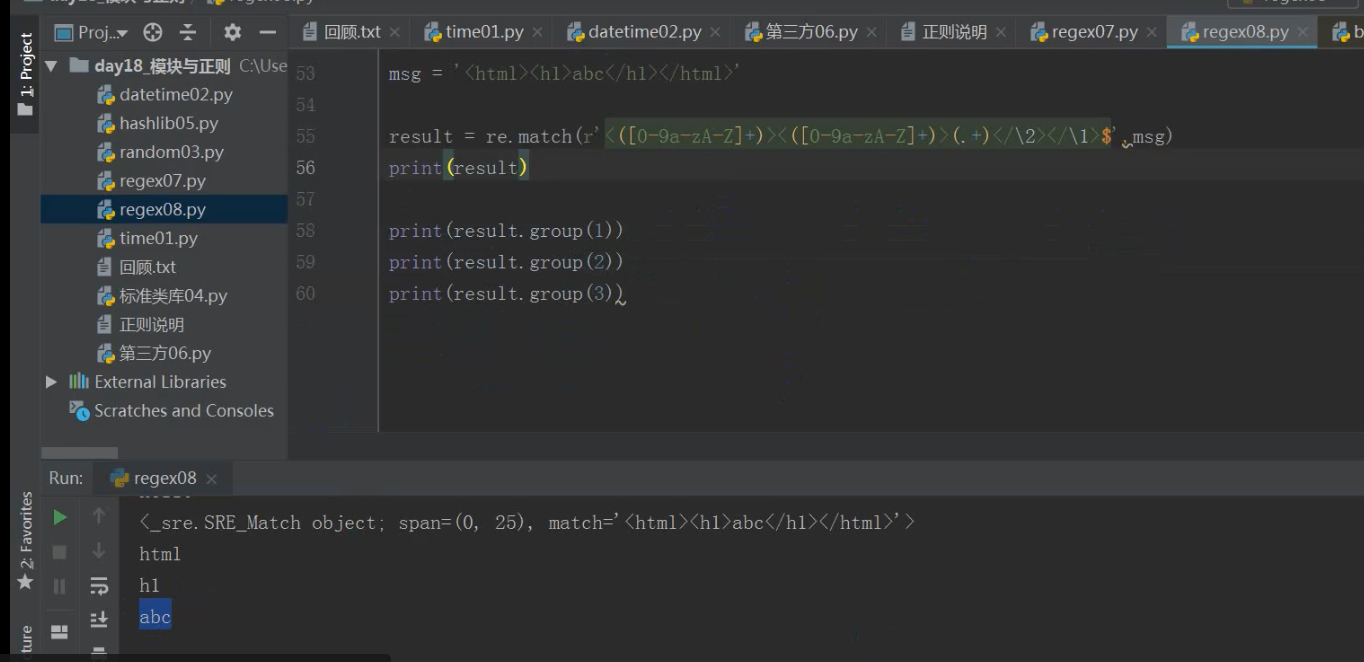
分享import re
msg = '<htm1><h1>abc</h1></html>'
result1 = re.match(r'<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>(.+)</\2></\1>',msg)
result = re.match(r'<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>(.+)<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>',msg)
print(result1)
print(result)