

34,876
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
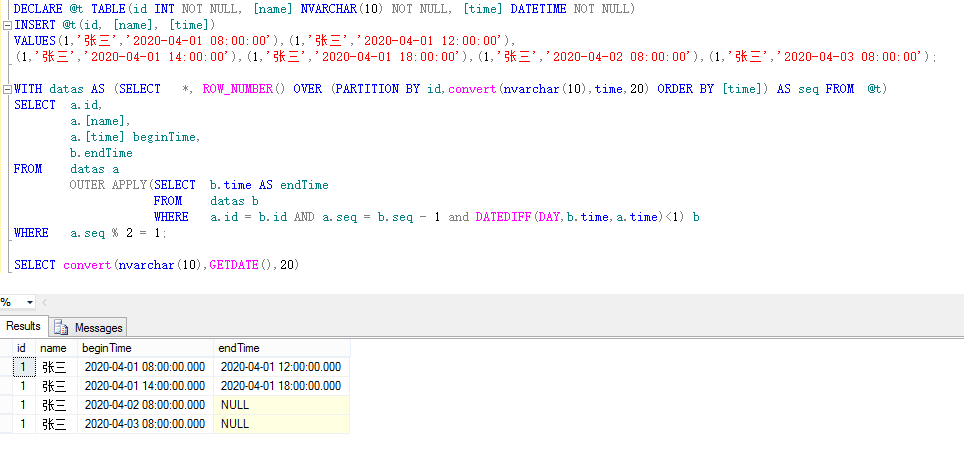
DECLARE @t TABLE(id INT NOT NULL, [name] NVARCHAR(10) NOT NULL, [time] DATETIME NOT NULL)
INSERT @t(id, [name], [time])
VALUES(1,'张三','2020-04-01 08:00:00'),(1,'张三','2020-04-01 12:00:00'),
(1,'张三','2020-04-01 14:00:00'),(1,'张三','2020-04-01 18:00:00'),(1,'张三','2020-04-02 08:00:00'),(1,'张三','2020-04-03 08:00:00');
WITH datas AS (SELECT *, ROW_NUMBER() OVER (PARTITION BY id,convert(nvarchar(10),time,20) ORDER BY [time]) AS seq FROM @t)
SELECT a.id,
a.[name],
a.[time] beginTime,
b.endTime
FROM datas a
OUTER APPLY(SELECT b.time AS endTime
FROM datas b
WHERE a.id = b.id AND a.seq = b.seq - 1 and DATEDIFF(DAY,b.time,a.time)<1) b
WHERE a.seq % 2 = 1;
 [/quote]
good 感谢你们提供的答案
[/quote]
good 感谢你们提供的答案

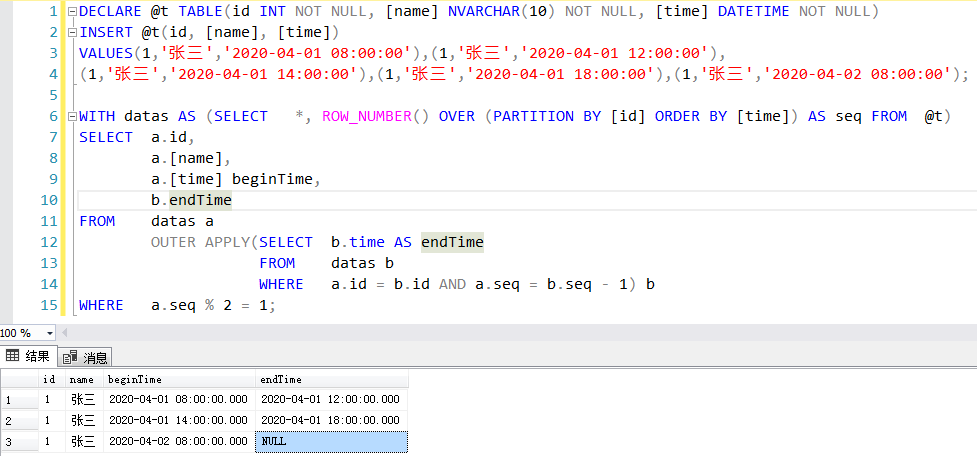
DECLARE @t TABLE(id INT NOT NULL, [name] NVARCHAR(10) NOT NULL, [time] DATETIME NOT NULL)
INSERT @t(id, [name], [time])
VALUES(1,'张三','2020-04-01 08:00:00'),(1,'张三','2020-04-01 12:00:00'),
(1,'张三','2020-04-01 14:00:00'),(1,'张三','2020-04-01 18:00:00'),(1,'张三','2020-04-02 08:00:00'),(1,'张三','2020-04-03 08:00:00');
WITH datas AS (SELECT *, ROW_NUMBER() OVER (PARTITION BY id,convert(nvarchar(10),time,20) ORDER BY [time]) AS seq FROM @t)
SELECT a.id,
a.[name],
a.[time] beginTime,
b.endTime
FROM datas a
OUTER APPLY(SELECT b.time AS endTime
FROM datas b
WHERE a.id = b.id AND a.seq = b.seq - 1 and DATEDIFF(DAY,b.time,a.time)<1) b
WHERE a.seq % 2 = 1;
DECLARE @t TABLE(id INT NOT NULL, [name] NVARCHAR(10) NOT NULL, [time] DATETIME NOT NULL)
INSERT @t(id, [name], [time])
VALUES(1,'张三','2020-04-01 08:00:00'),(1,'张三','2020-04-01 12:00:00'),
(1,'张三','2020-04-01 14:00:00'),(1,'张三','2020-04-01 18:00:00'),(1,'张三','2020-04-02 08:00:00');
WITH datas AS (SELECT *, ROW_NUMBER() OVER (PARTITION BY [id] ORDER BY [time]) AS seq FROM @t)
SELECT a.id,
a.[name],
a.[time] beginTime,
b.endTime
FROM datas a
OUTER APPLY(SELECT b.time AS endTime
FROM datas b
WHERE a.id = b.id AND a.seq = b.seq - 1) b
WHERE a.seq % 2 = 1;



