

111,129
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
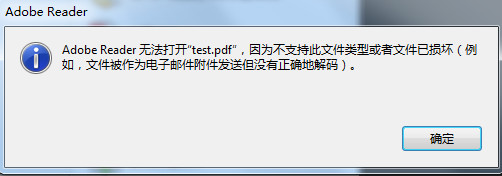

string s = Ole.ObjectType;
//"AcroExch.Document.11"是指PDF对象对应的ProgID
if (s == "AcroExch.Document.11")
{
File.WriteAllBytes("Result.pdf", Ole.NativeData);
}

