


37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享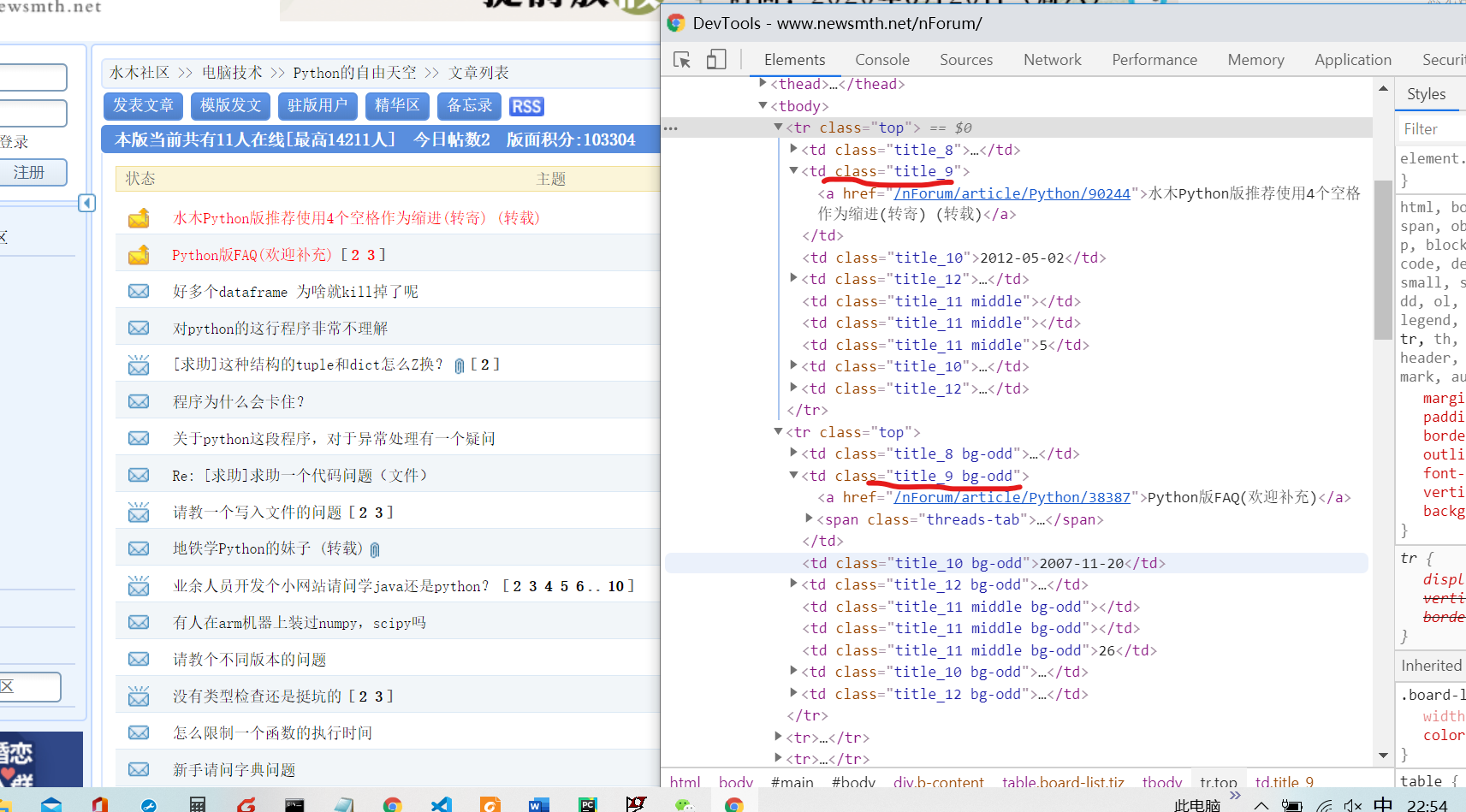



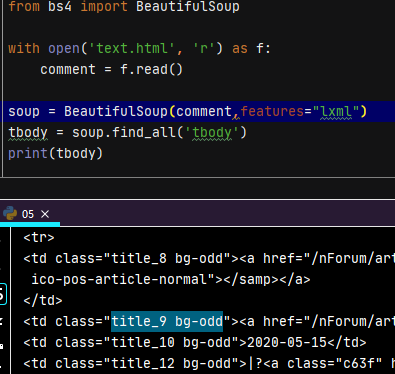
from bs4 import BeautifulSoup
html = """<body>
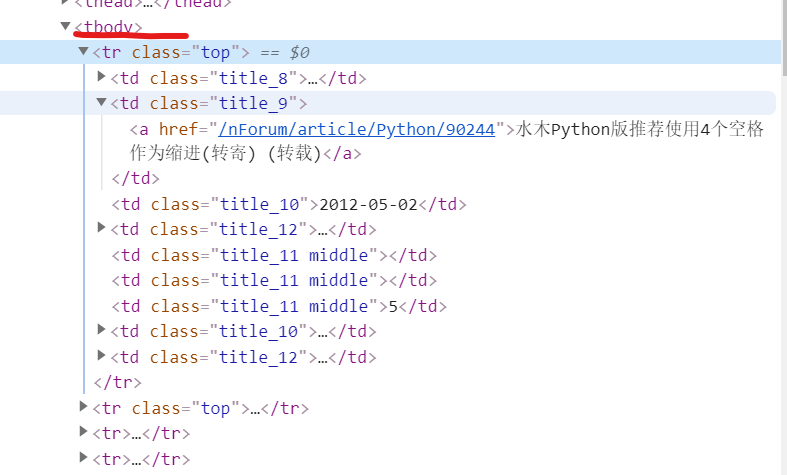
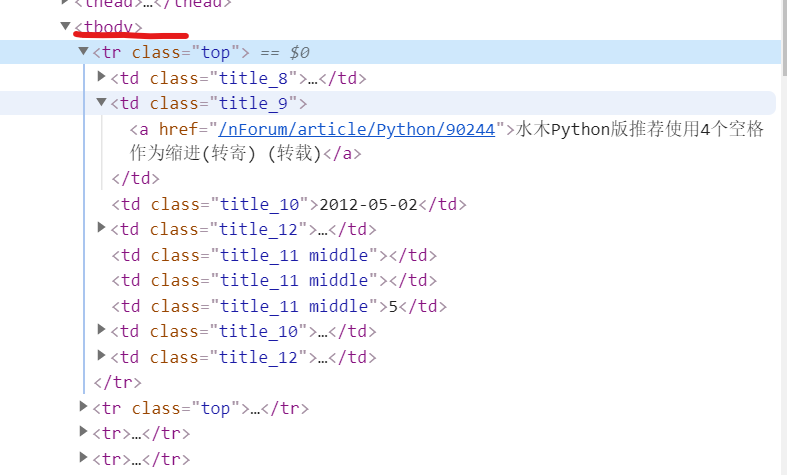
<tr class="top">
<td class="title_8">1</td>
<td class="title_9">2</td>
<td class="title_10">3</td>
<td class="title_11">4</td>
<td class="title_12">5</td>
</tr>
<tr class="top">
<td class="title_8 bg-odd">6</td>
<td class="title_9 bg-odd">7</td>
<td class="title_10 bg-odd">8</td>
<td class="title_11 bg-odd">9</td>
<td class="title_12 bg-odd">10</td>
<td class="title_11 middle bg-odd">11</td>
<td class="title_11 middle bg-odd">12</td>
<td class="title_11 middle bg-odd">13</td>
<td class="title_10 bg-odd">14</td>
<td class="title_12 bg-odd">15</td>
</tr>
</body>
"""
soup = BeautifulSoup(html, features='lxml')
td1 = soup.find_all('td', {'class': {'title_9 bg-odd'}})
print('td1>>>',td1)
td4 = soup.find_all('td', class_='title_9 bg-odd') # 这里只有一个空格时,可以查找到
print('td4>>>',td4)
td5 = soup.find_all('td', class_={'title_9 bg-odd'}) # 可以在带# 的这行代码中添加空号试一试
print('td5>>>',td5)
td6 = soup.find_all('td', class_=['title_9 bg-odd']) # 无论是哪种,引号内的都是字符串
print('td6>>>',td6)
td7 = soup.find_all('td', class_=['title_9','bg-odd']) # 无论是哪种,引号内的都是字符串
print('td7>>>',td7)
td2 = soup.find_all('td', {'class': 'title_9'})
print('td2>>>',td2)
td3 = soup.find_all('td', {'class': 'bg-odd'})
print('td3>>>',td3)
from bs4 import BeautifulSoup
html = """<body>
<tr class="top">
<td class="title_8">1</td>
<td class="title_9">2</td>
<td class="title_10">3</td>
<td class="title_11">4</td>
<td class="title_12">5</td>
</tr>
<tr class="top">
<td class="title_8 bg-odd">6</td>
<td class="title_9 bg-odd">7</td>
<td class="title_10 bg-odd">8</td>
<td class="title_11 bg-odd">9</td>
<td class="title_12 bg-odd">10</td>
<td class="title_11 middle bg-odd">11</td>
<td class="title_11 middle bg-odd">12</td>
<td class="title_11 middle bg-odd">13</td>
<td class="title_10 bg-odd">14</td>
<td class="title_12 bg-odd">15</td>
</tr>
</body>
"""
soup = BeautifulSoup(html, features='lxml')
td1 = soup.find_all('td', {'class': {'title_9 bg-odd'}})
print('td1>>>',td1)
td4 = soup.find_all('td', class_='title_9 bg-odd') # 这里只有一个空格时,可以查找到
print('td4>>>',td4)
td5 = soup.find_all('td', class_={'title_9 bg-odd'}) # 可以在带# 的这行代码中添加空号试一试
print('td5>>>',td5)
td6 = soup.find_all('td', class_=['title_9 bg-odd']) # 无论是哪种,引号内的都是字符串
print('td6>>>',td6)
td7 = soup.find_all('td', class_=['title_9','bg-odd']) # 无论是哪种,引号内的都是字符串
print('td7>>>',td7)
td2 = soup.find_all('td', {'class': 'title_9'})
print('td2>>>',td2)
td3 = soup.find_all('td', {'class': 'bg-odd'})
print('td3>>>',td3)


