34,876
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
CREATE TABLE [dbo].[test_yj](
[rq] [datetime] NOT NULL, --日期不会重复
[khbh] [varchar](50) NULL, --客户编号
[fkfs] [varchar](50) NULL, --付款方式
[je] [money] NULL, --金额
CONSTRAINT [PK_test_yj] PRIMARY KEY CLUSTERED
(
[rq] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
go
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-01 08:20:00.000','B','支付宝',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-01 15:20:00.000','A','现金',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-02 05:20:00.000','A','微信',200.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-02 08:20:00.000','B','微信',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-03 08:20:00.000','B','微信',200.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-03 15:20:00.000','A','支付宝',300.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-04 08:20:00.000','B','支付宝',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-04 15:20:00.000','A','现金',150.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-05 08:20:00.000','B','现金',200.00)



CREATE TABLE [dbo].[test_yj](
[rq] [datetime] NOT NULL, --日期不会重复
[khbh] [varchar](50) NULL, --客户编号
[fkfs] [varchar](50) NULL, --付款方式
[je] [money] NULL, --金额
CONSTRAINT [PK_test_yj] PRIMARY KEY CLUSTERED
(
[rq] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
go
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-01 08:20:00.000','B','支付宝',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-01 15:20:00.000','A','现金',1200.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-02 05:20:00.000','A','微信',200.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-02 08:20:00.000','B','微信',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-03 08:20:00.000','B','微信',200.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-03 15:20:00.000','A','支付宝',300.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-04 08:20:00.000','B','支付宝',100.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-04 15:20:00.000','A','现金',150.00)
insert test_yj (rq,khbh,fkfs,je) values ( '2020-06-05 08:20:00.000','B','现金',200.00)
create table #xf(
[khbh] varchar(13),
[xfje] numeric(16,6))
insert into #xf select 'A',20
insert into #xf select 'B',150
insert into #xf select 'C',180
select *,row_number() over(partition by khbh order by rq) as num
into #yj2
from test_yj
select * from #yj2
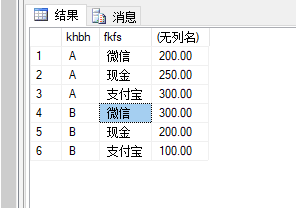
select a.rq,khbh,fkfs,case when 排序=1 then 余额 else je end as je from
(select rq,khbh,fkfs,row_number()over(partition by khbh order by rq)排序,je,余额 from (
select *,累计-xfje as 余额 from (
select a.*,sum(je)over(partition by a.khbh order by num)累计,b.xfje from #yj2 a left join #xf b on a.khbh=b.khbh )a where 累计>=xfje)a )a