社区
其他开发语言
帖子详情
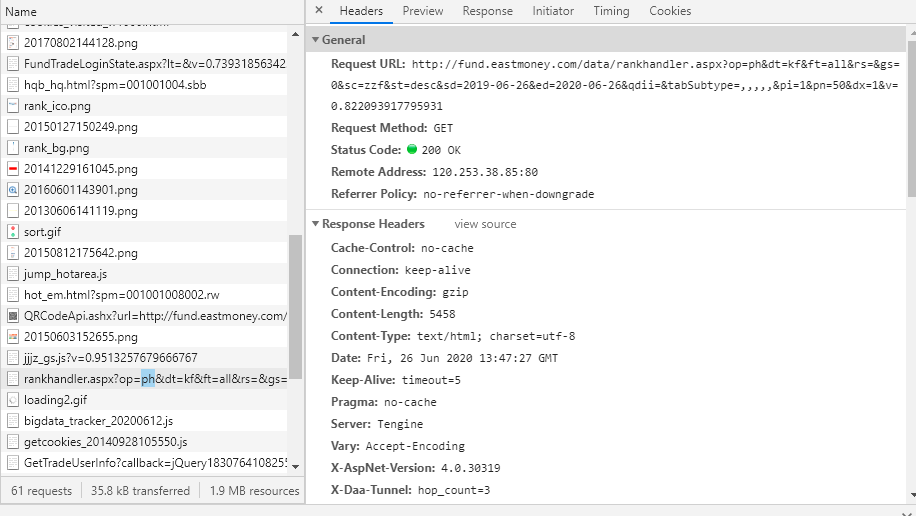
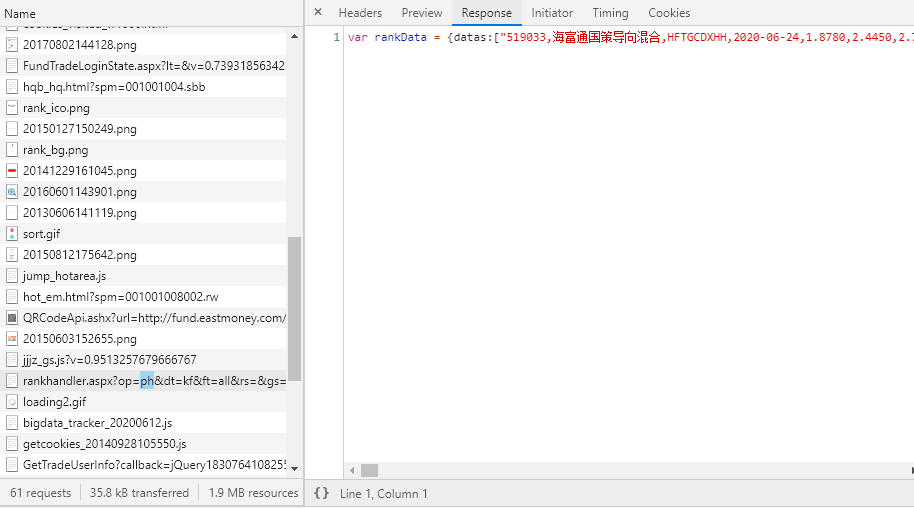
python爬虫抓包获取Request URL访问response内容“无访问权限”
weixin_44813698
2020-06-26 11:38:44
python爬虫抓包获取Request URL访问response内容“无访问权限”,但是response中确实是有内容的,我却没有权限访问,请问这是网站的反爬虫机制还是其他问题,欢迎大佬解答。
...全文
1338
7
打赏
收藏
python爬虫抓包获取Request URL访问response内容“无访问权限”
python爬虫抓包获取Request URL访问response内容“无访问权限”,但是response中确实是有内容的,我却没有权限访问,请问这是网站的反爬虫机制还是其他问题,欢迎大佬解答。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
7 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
想吃海底捞
2021-05-02
打赏
举报
回复
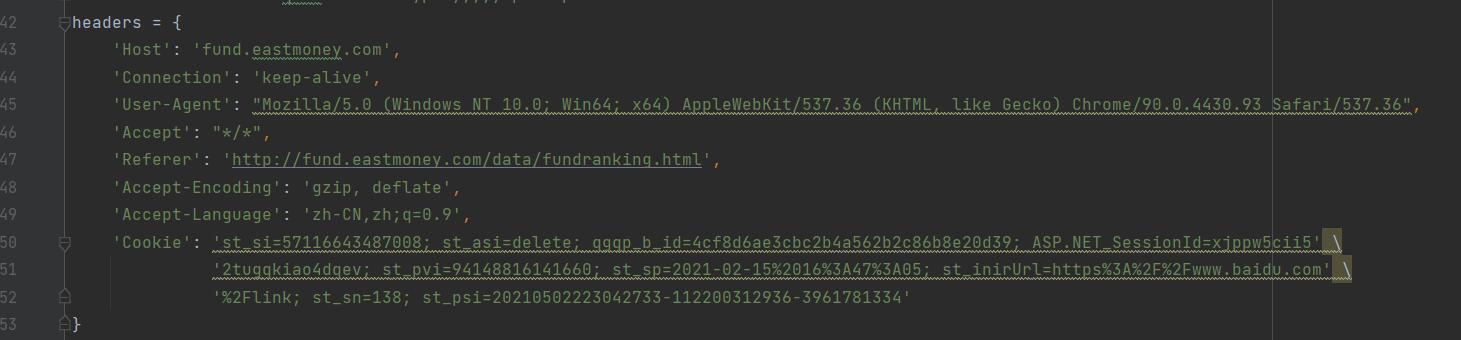
把headers全加上就行了(不能只加user-agent),实测可行
想吃海底捞
2021-05-02
打赏
举报
回复
楼主问题解决了吗,遇到同样的问题了
北雁Irene
2021-03-31
打赏
举报
回复
同问,如何解决?
董大侠debade
2021-03-23
打赏
举报
回复
你好,问题解决了,遇见同样问题了
weixin_44813698
2020-06-30
打赏
举报
回复
你好,以前的url里边response里边的内容是可以通过url直接访问的,我写代码解析resonse的内容就行了,现在response的内容获取不到了,程序自然不能正确运行了,我的意思是问为什么response的内容没有访问权限了,这是什么原因?
晚风_END
2020-06-28
打赏
举报
回复
兄弟。人才啊,敢把报错信息完整的发出来吗??你这样问 问题没几个人愿意回答的。控制台报错信息复制一下很难吗???
孤卷残梦饮一池恨
2020-06-27
打赏
举报
回复
加cookies试试
Python
入门网络
爬虫
之精华版
Python
入门网络
爬虫
之精华版
Python
学习网络
爬虫
主要分3个大的版块:抓取,分析,存储 另外,比较常用的
爬虫
框架Scrapy,这里最后也详细介绍一下。 首先列举一下本人总结的相关文章,这些覆盖了入门网络
爬虫
需要的基本概念和技巧:宁哥的小站-网络
爬虫
当我们在浏览器中输入一个
url
后回车,后台会发生什么?比如说你输入http://www.lining0806.com/,你就会看到宁哥的小站首页。 简单来说这段过程发生了以下四个步骤: 查找域名对应的IP地址。 向IP对应的服务器发送请求。 服务器响应请求,发回网页
内容
。 浏览器解析网页
内容
。 网络
爬虫
要做的,简单来说,就是实现浏览器的功能。通过指定
url
,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器
获取
。 抓取 这一步,你要明确要得到的
内容
是什么?是HTML源码,还是Json格式的字符串等。 1. 最基本的抓取 抓取大多数情况属于get请求,即直接从对方服务器上
获取
数据。 首先,
Python
中自带
url
lib及
url
lib2这两个模块,基本上能满足一般的页面抓取。另外,
request
s也是非常有用的包,与此类似的,还有httplib2等等。
Request
s: import
request
s
response
=
request
s.get(
url
) content =
request
s.get(
url
).content print "
response
headers:",
response
.headers print "content:", content
Url
lib2: import
url
lib2
response
=
url
lib2.
url
open(
url
) content =
url
lib2.
url
open(
url
).read() print "
response
headers:",
response
.headers print "content:", content Httplib2: import httplib2 http = httplib2.Http()
response
_headers, content = http.
request
(
url
, 'GET') print "
response
headers:",
response
_headers print "content:", content 此外,对于带有查询字段的
url
,get请求一般会将来请求的数据附在
url
之后,以?分割
url
和传输数据,多个参数用&连接。 data = {'data1':'XXXXX', 'data2':'XXXXX'}
Request
s:data为dict,json import
request
s
response
=
request
s.get(
url
=
url
, params=data)
Url
lib2:data为string import
url
lib,
url
lib2 data =
url
lib.
url
encode(data) full_
url
=
url
+'?'+data
response
=
url
lib2.
url
open(full_
url
) 相关参考:网易新闻排行榜抓取回顾 参考项目:网络
爬虫
之最基本的
爬虫
:爬取网易新闻排行榜 2. 对于登陆情况的处理 2.1 使用表单登陆 这种情况属于post请求,即先向服务器发送表单数据,服务器再将返回的cookie存入本地。 data = {'data1':'XXXXX', 'data2':'XXXXX'}
Request
s:data为dict,json import
request
s
response
=
request
s.post(
url
=
url
, data=data)
Url
lib2:data为string import
url
lib,
url
lib2 data =
url
lib.
url
encode(data) req =
url
lib2.
Request
(
url
=
url
, data=data)
response
=
url
lib2.
url
open(req) 2.2 使用cookie登陆 使用cookie登陆,服务器会认为你是一个已登陆的用户,所以就会返回给你一个已登陆的
内容
。因此,需要验证码的情况可以使用带验证码登陆的cookie解决。 import
request
s
request
s_session =
request
s.session()
response
=
request
s_session.post(
url
=
url
_login, data=data) 若存在验证码,此时采用
response
=
request
s_session.post(
url
=
url
_login, data=data)是不行的,做法应该如下:
response
_captcha =
request
s_session.get(
url
=
url
_login, cookies=cookies)
response
1 =
request
s.get(
url
_login) # 未登陆
response
2 =
request
s_session.get(
url
_login) # 已登陆,因为之前拿到了
Response
Cookie!
response
3 =
request
s_session.get(
url
_results) # 已登陆,因为之前拿到了
Response
Cookie! 相关参考:网络
爬虫
-验证码登陆 参考项目:网络
爬虫
之用户名密码及验证码登陆:爬取知乎网站 3. 对于反
爬虫
机制的处理 3.1 使用代理 适用情况:限制IP地址情况,也可解决由于“频繁点击”而需要输入验证码登陆的情况。 这种情况最好的办法就是维护一个代理IP池,网上有很多免费的代理IP,良莠不齐,可以通过筛选找到能用的。对于“频繁点击”的情况,我们还可以通过限制
爬虫
访问
网站的频率来避免被网站禁掉。 proxies = {'http':'http://XX.XX.XX.XX:XXXX'}
Request
s: import
request
s
response
=
request
s.get(
url
=
url
, proxies=proxies)
Url
lib2: import
url
lib2 proxy_support =
url
lib2.ProxyHandler(proxies) opener =
url
lib2.build_opener(proxy_support,
url
lib2.HTTPHandler)
url
lib2.install_opener(opener) # 安装opener,此后调用
url
open()时都会使用安装过的opener对象
response
=
url
lib2.
url
open(
url
) 3.2 时间设置 适用情况:限制频率情况。
Request
s,
Url
lib2都可以使用time库的sleep()函数: import time time.sleep(1) 3.3 伪装成浏览器,或者反“反盗链” 有些网站会检查你是不是真的浏览器
访问
,还是机器自动
访问
的。这种情况,加上User-Agent,表明你是浏览器
访问
即可。有时还会检查是否带Referer信息还会检查你的Referer是否合法,一般再加上Referer。 headers = {'User-Agent':'XXXXX'} # 伪装成浏览器
访问
,适用于拒绝
爬虫
的网站 headers = {'Referer':'XXXXX'} headers = {'User-Agent':'XXXXX', 'Referer':'XXXXX'}
Request
s:
response
=
request
s.get(
url
=
url
, headers=headers)
Url
lib2: import
url
lib,
url
lib2 req =
url
lib2.
Request
(
url
=
url
, headers=headers)
response
=
url
lib2.
url
open(req) 4. 对于断线重连 不多说。 def multi_session(session, *arg): retryTimes = 20 while retryTimes>0: try: return session.post(*arg) except: print '.', retryTimes -= 1 或者 def multi_open(opener, *arg): retryTimes = 20 while retryTimes>0: try: return opener.open(*arg) except: print '.', retryTimes -= 1 这样我们就可以使用multi_session或multi_open对
爬虫
抓取的session或opener进行保持。 5. 多进程抓取 这里针对华尔街见闻进行并行抓取的实验对比:
Python
多进程抓取 与 Java单线程和多线程抓取 相关参考:关于
Python
和Java的多进程多线程计算方法对比 6. 对于Ajax请求的处理 对于“加载更多”情况,使用Ajax来传输很多数据。 它的工作原理是:从网页的
url
加载网页的源代码之后,会在浏览器里执行JavaScript程序。这些程序会加载更多的
内容
,“填充”到网页里。这就是为什么如果你直接去爬网页本身的
url
,你会找不到页面的实际
内容
。 这里,若使用Google Chrome分析”请求“对应的链接(方法:右键→审查元素→Network→清空,点击”加载更多“,出现对应的GET链接寻找Type为text/html的,点击,查看get参数或者复制
Request
URL
),循环过程。 如果“请求”之前有页面,依据上一步的网址进行分析推导第1页。以此类推,抓取抓Ajax地址的数据。 对返回的json格式数据(str)进行正则匹配。json格式数据中,需从'\uxxxx'形式的unicode_escape编码转换成u'\uxxxx'的unicode编码。 7. 自动化测试工具Selenium Selenium是一款自动化测试工具。它能实现操纵浏览器,包括字符填充、鼠标点击、
获取
元素、页面切换等一系列操作。总之,凡是浏览器能做的事,Selenium都能够做到。 这里列出在给定城市列表后,使用selenium来动态抓取去哪儿网的票价信息的代码。 参考项目:网络
爬虫
之Selenium使用代理登陆:爬取去哪儿网站 8. 验证码识别 对于网站有验证码的情况,我们有三种办法: 使用代理,更新IP。 使用cookie登陆。 验证码识别。 使用代理和使用cookie登陆之前已经讲过,下面讲一下验证码识别。 可以利用开源的Tesseract-OCR系统进行验证码图片的下载及识别,将识别的字符传到
爬虫
系统进行模拟登陆。当然也可以将验证码图片上传到打码平台上进行识别。如果不成功,可以再次更新验证码识别,直到成功为止。 参考项目:Captcha1 爬取有两个需要注意的问题: 如何监控一系列网站的更新情况,也就是说,如何进行增量式爬取? 对于海量数据,如何实现分布式爬取? 分析 抓取之后就是对抓取的
内容
进行分析,你需要什么
内容
,就从中提炼出相关的
内容
来。 常见的分析工具有正则表达式,BeautifulSoup,lxml等等。 存储 分析出我们需要的
内容
之后,接下来就是存储了。 我们可以选择存入文本文件,也可以选择存入MySQL或MongoDB数据库等。 存储有两个需要注意的问题: 如何进行网页去重?
内容
以什么形式存储? Scrapy Scrapy是一个基于Twisted的开源的
Python
爬虫
框架,在工业中应用非常广泛。 相关
内容
可以参考基于Scrapy网络
爬虫
的搭建,同时给出这篇文章介绍的微信搜索爬取的项目代码,给大家作为学习参考。 参考项目:使用Scrapy或
Request
s递归抓取微信搜索结果
『
Python
爬虫
』
抓包
工具 Fiddler 入门教程
如今
Python
爬虫
越来越火,有想学好
Python
爬虫
的小伙伴可以前往gzh【
Python
编程学习圈】领取系统的学习资料以及教程视频,还分享有大量的技术干货文章可以阅读学习,欢迎大家关注学习。 传统的
抓包
工具,如:Fiddler、Charles、Wireshark、Tcpdump,大家肯定都不陌生了; 今天我们就来聊一聊这款常用的
抓包
工具:Fiddler; fiddler简介 Fiddler是个蛮好用的
抓包
工具,也是比较好用的web代理调试工具之一; 它能记录并检查所有客户端与服务端的HTTP/.
Python
爬虫
抓包
工具使用
Python
爬虫
抓包
工具使用 一. 常用的工具
python
pycharm 浏览器 chrome 火狐 fiddler 2 fiddler的使用 二. 操作界面 三.界面含义 1. 请求 (
Request
) 部分详解 2. 响应 (
Response
) 部分详解 四. 设置 1. 如何打开 启动Fiddler,打开菜单栏中的 Tools >Options,打开“Fiddler Options”对话框 2. 设置 Capture HTTPS CONNECTs 捕捉HTTPS连接 Dec
python
爬虫
获取
真实
url
_
Python
3
爬虫
-提取请求页面所有的真实
url
-BeautifulSoup
方法一:find_allimport
url
libimport
request
sfrom
url
lib.parse import
url
parsefrom
url
lib import
request
, parsefrom bs4 import BeautifulSoupword = '周杰伦'# word为关键词,pn是百度用来分页的..
url
= 'http://www.baidu.com.cn...
python
爬虫
抓包
工具_
Python
爬虫
-02:HTTPS请求与响应,以及
抓包
工具Fiddler的使用
1. HTTP和HTTPSHTTP: 一种发布和接受HTML页面方法,端口号为80HTTPS: HTTP的安全版,在HTTP上加入了SSL层,端口号为443SSL: 用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全网络
爬虫
可以理解为模拟浏览器操作的过程浏览器的主要功能是向服务器发送请求,在浏览器窗口展示您选择的网络资源,HTTP是一套计算机通过网络进行通...
其他开发语言
3,423
社区成员
15,635
社区内容
发帖
与我相关
我的任务
其他开发语言
其他开发语言 其他开发语言
复制链接
扫一扫
分享
社区描述
其他开发语言 其他开发语言
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享