18,772
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
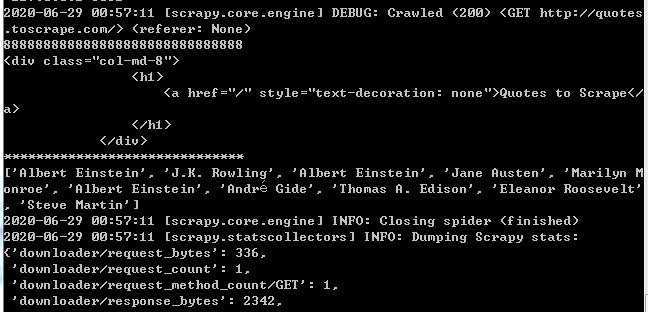
分享import scrapy
class Quote_Spider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['http://quotes.toscrape.com/']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
content = response.xpath("//div[@class='col-md-8']")
print("8"*30)
print(content[0].extract())
print('*'*30)
print(content[0].xpath("//div//small/text()").extract())