import jieba
txt=open("红楼梦.txt","r",encoding='utf-8').read()
words= jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
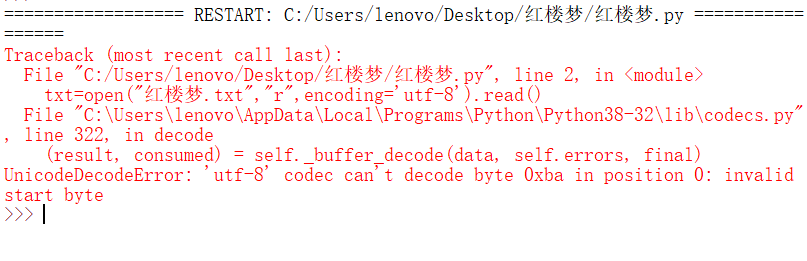
求问这是哪里出现什么问题了呀?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


 为什么王夫人那一行的格式和别的不一样呢?
为什么王夫人那一行的格式和别的不一样呢?
