1.一次性全部爬取省市区街道的数据代码如下所示:
存在缺陷就是数据量太大容易导致爬取的时候出行丢失部分,补充比较麻烦
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
txt = urllib.request.urlopen(url + indexs).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
lista = soup.find_all('a')
lista.pop()
for a in lista:
#输出省
print("s_"+a['href'][0:2] + " " + a.text)
time.sleep(1)
txt = urllib.request.urlopen(url + a['href'],timeout=5000).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
listb = soup.find_all('a')
listb.pop()
bb = {}
l = len(listb)
#print("----->>>>> "+str(l/2)+" <<<<<<------")
strName = ''
for i in range(0,l-1):
if(listb[i].text == strName) :
continue
strIndex = listb[i]['href']
code = listb[i].text
codecity = code
strName = name = listb[i+1].text
#print(strIndex+","+code +"," + name)
#输出市级
print(code + " " + name + " s_"+strIndex[0:2])
##街道url地址
url2 = url+strIndex[0:2]+'/'
time.sleep(1)
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#输出区级
print(code + " " + name + " " + " "+codecity)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("")
continue
#居委会
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此处居委会数据还存在问题,暂时不研究了.根据你们自己需要进行配置
# 输出居委会
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 输出街道
print(code + " " + name + " " + " " + codeArea)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#变量对象
areaBl.fn()
2.按省份方式爬取,以北京为例代码如下:
网络请求不稳定的情况也会存在少数数据缺失,所以需要进行检查再配合以3按城市的方式进行爬取.数据量越少越容易爬取
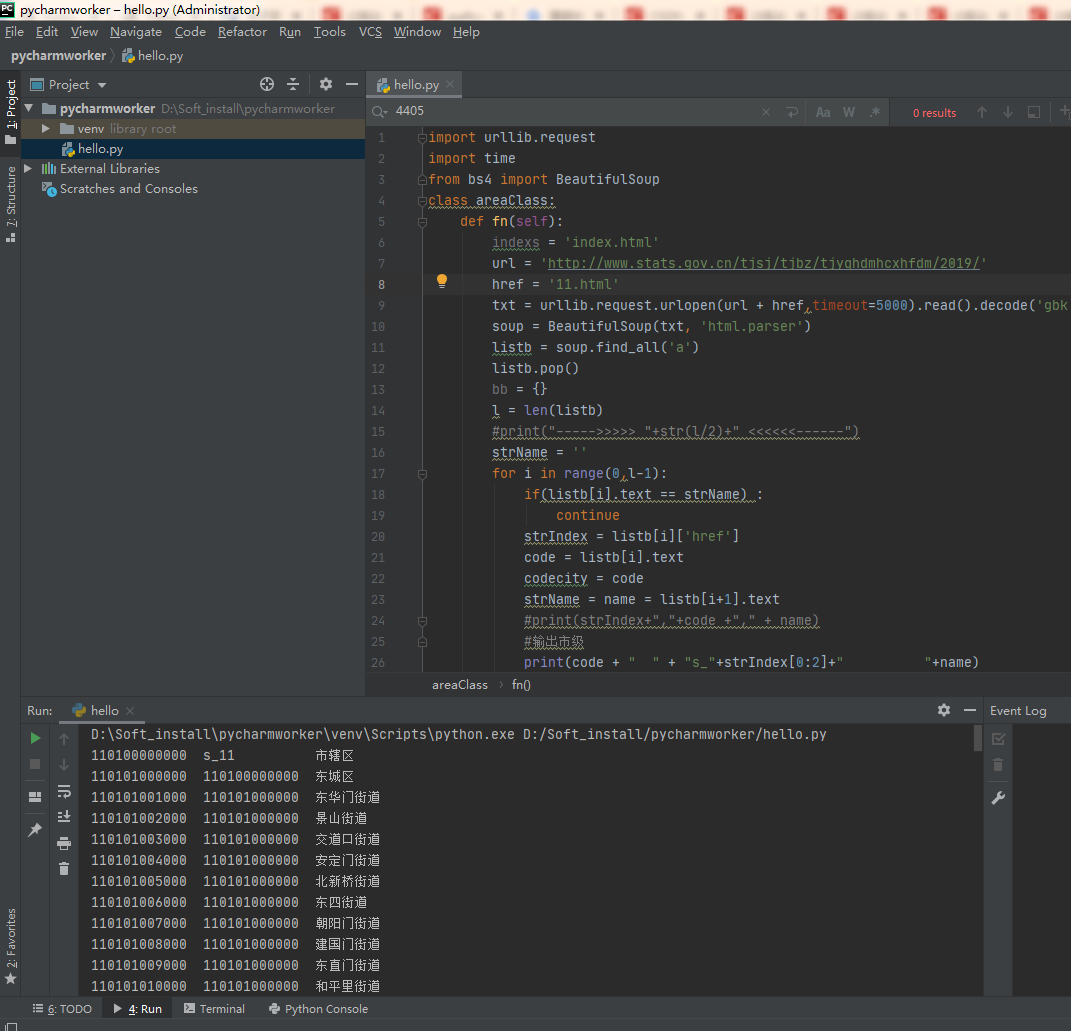
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
href = '11.html'
txt = urllib.request.urlopen(url + href,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
listb = soup.find_all('a')
listb.pop()
bb = {}
l = len(listb)
#print("----->>>>> "+str(l/2)+" <<<<<<------")
strName = ''
for i in range(0,l-1):
if(listb[i].text == strName) :
continue
strIndex = listb[i]['href']
code = listb[i].text
codecity = code
strName = name = listb[i+1].text
#print(strIndex+","+code +"," + name)
#输出市级
print(code + " " + "s_"+strIndex[0:2]+" "+name)
##街道url地址
url2 = url+strIndex[0:2]+'/'
time.sleep(1)
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#输出区级
print(code + " " + codecity + " " + name)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("")
continue
#居委会
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此处居委会数据还存在问题,暂时不研究了.根据你们自己需要进行配置
# 输出居委会
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 输出街道
print(code + " " + codeArea + " " + name)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#变量对象
areaBl.fn()
3.按市爬取数据代码如下:
这种方式爬取的数据一般而言都是不会存在问题的,除了个别市可能数据量大或者网络请求不稳定.也可以重新请求一次进行重新编译
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
strIndex = '13/1301.html'
url2 = url+strIndex[0:2]+'/'
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
codecity = '130600000000'
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#输出区级
print(code + " " + codecity + " " + name)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("错误")
#居委会
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此处居委会数据还存在问题,暂时不研究了.根据你们自己需要进行配置
# 输出居委会
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 输出街道
print(code + " " + codeArea + " " + name)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#变量对象
areaBl.fn()



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
