先上代码:
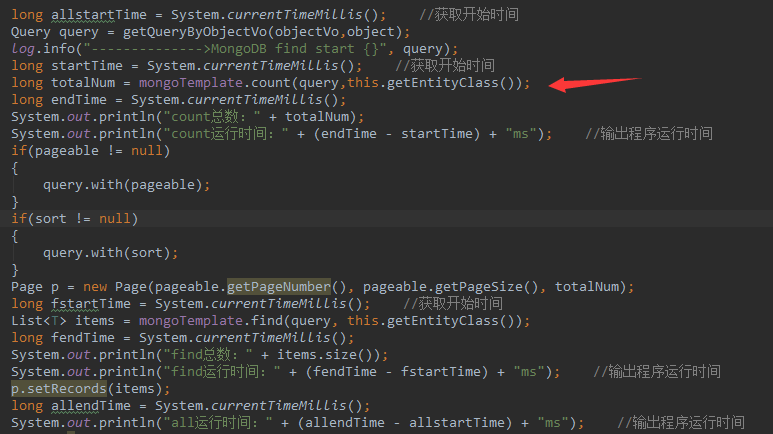
数据量大概在1600W左右,
情况1:不加任何条件的情况下
count总数:16907883
count运行时间:4ms
find总数:10
find运行时间:8ms
all运行时间:13ms
情况2:加上时间段条件的情况下
MongoDB find start Query: { "$and" : [{ "createTime" : { "$gte" : { "$date" : 1595952000000}}}, { "createTime" : { "$lte" : { "$date" : 1596470400000}}}]}, Fields: {}, Sort: {}
count总数:10993965
count运行时间:22470ms
find总数:10
find运行时间:9ms
all运行时间:22482ms
说明: createTime字段是加了索引的
情况3: 根据全文索引查询,结果数据较少的情况
MongoDB find start Query: { "$text" : { "$search" : "111"}}, Fields: {}, Sort: {}
count总数:53
count运行时间:153ms
find总数:10
find运行时间:6ms
all运行时间:161ms
情况4: 根据全文索引字段查询,数据较多的情况(几乎上千万)
MongoDB find start Query: { "$text" : { "$search" : "1"}}, Fields: {}, Sort: {}
等待实在太长,不统计了
疑问:
1、count方法在加上条件时非常耗时,因为没走索引??
因为是时间段查询 所以使用了如下方式进行条件拼装,
criteria.andOperator(
criteria.where(filedBtwBegin.replace("_begin","")).gte(filedBtwBeginValue),
criteria.where(filedBtwEnd.replace("_end","")).lte(filedBtwEndValue)
);
2、集合中加了全文索引字段,在查出大数据量是非常慢,有什么方法可以优化??全文索引已经生效了,通过全文索引的规则能查询出数据,但是就是很慢
3、因为项目做了分页,所以如果数据量很大,当点到最后一页时,有时非常非常卡,但是这个和count方法无关了,而且分页查询慢
请教各位指点,谢谢



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

