def get_url(html):
url_list = []
pattern = re.compile("this.id,'(.*?)'", re.S)
ids = pattern.findall(html)
for id in ids:
url_list.append('http://www.wanfangdata.com.cn/details/detail.do?_type=conference&id=' + id)
return url_list
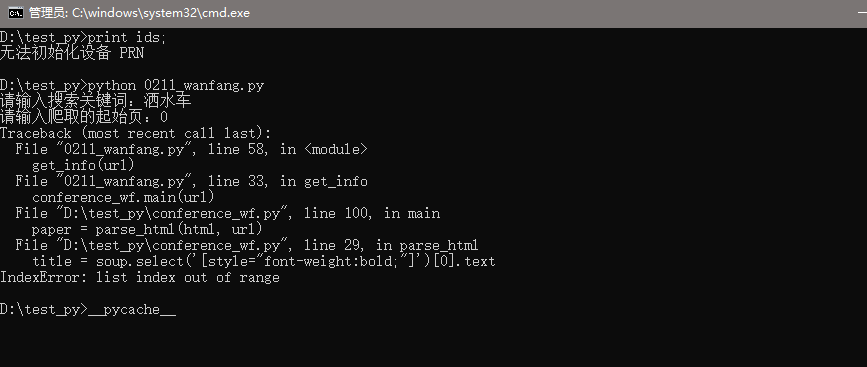
个人感觉是这一部分问题,但是不太懂,小白刚开始学习


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


