

37,743
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享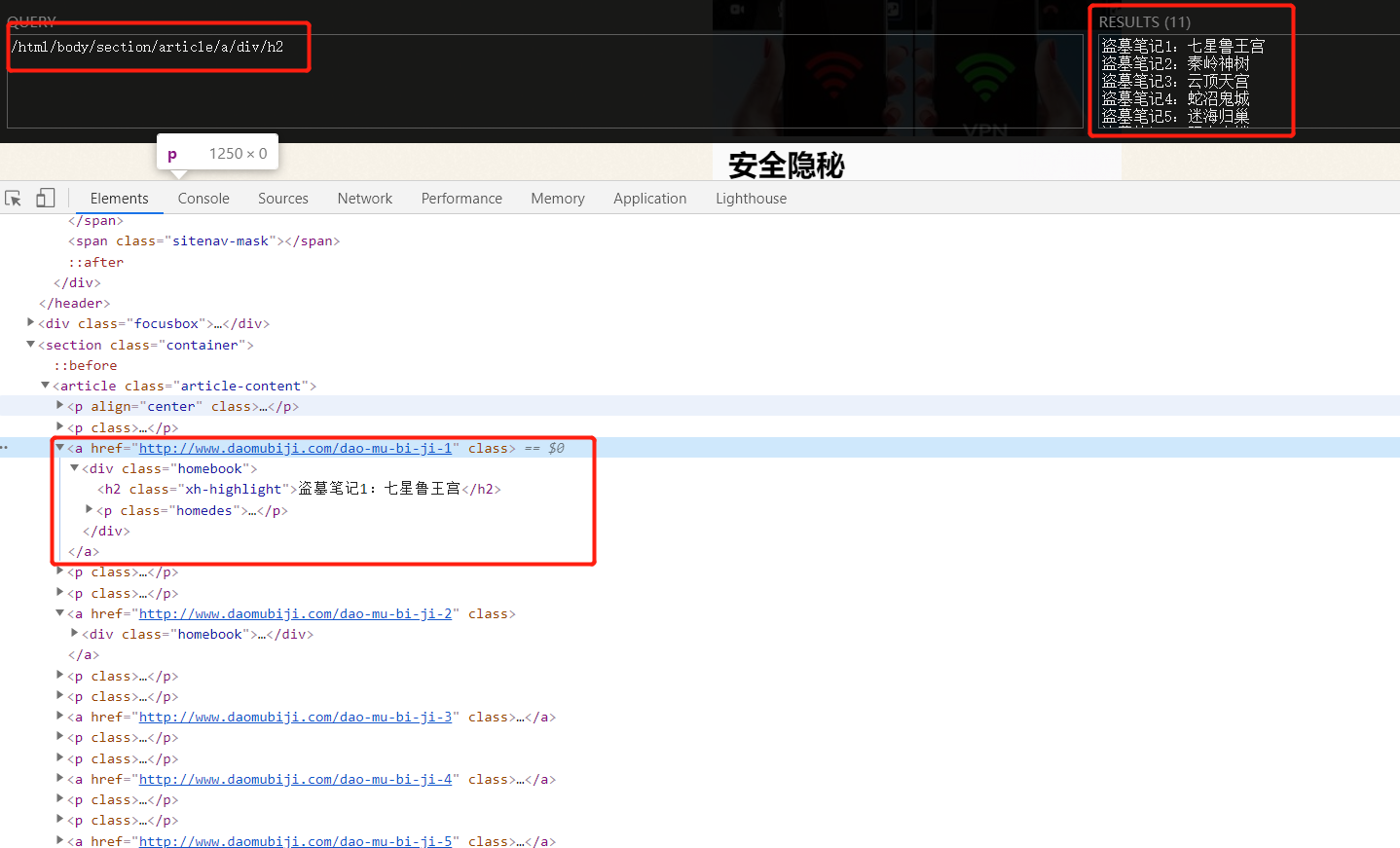
import requests
from lxml import etree
city_url = "http://www.daomubiji.com/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"}
response = requests.get(url=city_url,headers=headers)
html = etree.HTML(response.text)
result = html.xpath('/html/body/section/article/a/div/h2/text()')
print(result)
# 结果为空 []

这是一个集合,得用list列表接,把这个集合保存到一个变量中,然后循环得到每个Text()



