568
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Windows10 64位
Tensorflow1.15
Tensorflow object detection API 1.x
Python3.6.5
VS2015 VC++
CUDA10.0CPUi7
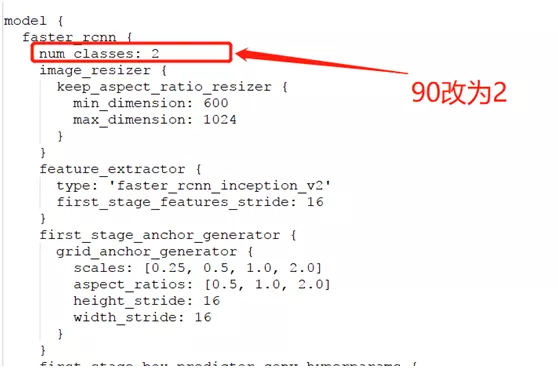
GPU 1050tihttps://pan.baidu.com/s/1UbFkGm4EppdAU660Vu7SdQitem {
id: 1
name: 'hat'
}
item {
id: 2
name: 'person'
}



- frozen_inference_graph.pb
- frozen_inference_graph.pbtxtpython mo_tf.py
--input_model D:\safehat_train\models\train\frozen_inference_graph.pb /
--transformations_config extensions\front\tf\faster_rcnn_support_api_v1.15.json /
--tensorflow_object_detection_api_pipeline_config D:\safehat_train\models\pipeline.config /
--input_shape [1,600,600,3] /
--reverse_input_channelsfrom __future__ import print_function
import cv2
import time
import logging as log
from openvino.inference_engine import IECore
labels = ["hat", "person"]
def safehat_detection():
model_xml = "D:/projects/opencv_tutorial/data/models/safetyhat/frozen_inference_graph.xml"
model_bin = "D:/projects/opencv_tutorial/data/models/safetyhat/frozen_inference_graph.bin"
log.info("Creating Inference Engine")
ie = IECore()
# Read IR
net = ie.read_network(model=model_xml, weights=model_bin)
log.info("Preparing input blobs")
input_it = iter(net.input_info)
input1_blob = next(input_it)
input2_blob = next(input_it)
print(input2_blob)
out_blob = next(iter(net.outputs))
# Read and pre-process input images
print(net.input_info[input1_blob].input_data.shape)
print(net.input_info[input2_blob].input_data.shape)
image = cv2.imread("D:/safehat/test/1.jpg")
ih, iw, ic = image.shape
image_blob = cv2.dnn.blobFromImage(image, 1.0, (600, 600), (0, 0, 0), False)
# Loading model to the plugin
exec_net = ie.load_network(network=net, device_name="CPU")
# Start sync inference
log.info("Starting inference in synchronous mode")
inf_start1 = time.time()
res = exec_net.infer(inputs={input1_blob:[[600, 600, 1.0]], input2_blob: [image_blob]})
inf_end1 = time.time() - inf_start1
print("inference time(ms) : %.3f" % (inf_end1 * 1000))
# Processing output blob
res = res[out_blob]
for obj in res[0][0]:
if obj[2] > 0.5:
index = int(obj[1])
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
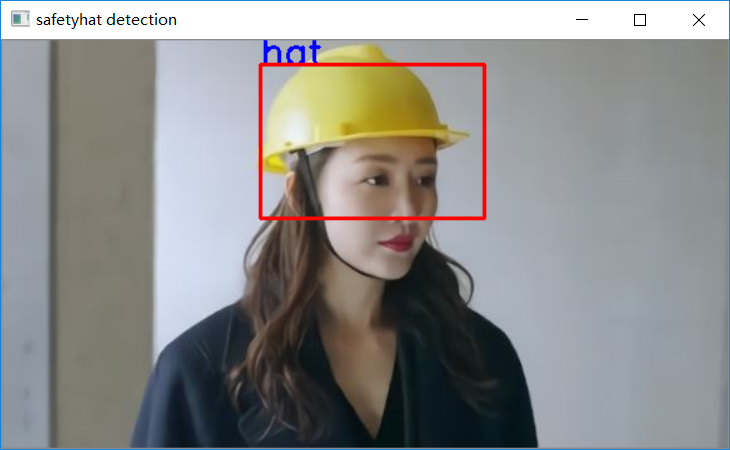
cv2.putText(image,labels[index-1], (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 2)
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2, 8, 0)
cv2.imshow("safetyhat detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
safehat_detection()