

37,743
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享printinputpython
weight=80
height=1.75
bmi= weight/height^2
if bmi<18.5:
print("过轻")
if 18.5<=bmi>=25:
print("正常")
elif 25<bmi>28:
print("过重")
elif 28<=bmi>=32:
print("肥胖")
elif bmi>32:
print("严重肥胖")pow(a,b)weight=input("weight:")
height=input("height:")
bmi= weight/height**2
if bmi<18.5:
print("过轻")
if 18.5<=bmi>=25:
print("正常")
elif 25<bmi>28:
print("过重")
elif 28<=bmi>=32:
print("肥胖")
elif bmi>32:
print("严重肥胖")input()strstrstrint()python
a= input("weight:")
b= input("height:")
weight=int(a)
height=int(b)
bmi= weight/height**2
if bmi<18.5:
print("过轻")
elif 18.5<=bmi>=25:
print("正常")
elif 25<bmi>28:
print("过重")
elif 28<=bmi>=32:
print("肥胖")
else :
print("严重肥胖")int()float()

names = ['Mike', 'Bob', 'Alice']
scores = [95, 80, 85]>>>d = {'Mike': 95, 'Bob': 80, 'Alice': 85}
>>>d['Mike']
95>>>d['Mike'] = 90
>>>d['Mike']
90>>>d['Jack'] = 90
>>>d['Jack']
90
>>>d['Jack'] = 88
>>>d['Jack']
88>>>d['小明']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: '小明'>>>'小明' in d
False>>>d.get('小明')
>>>d.get('小明', -1)
-1>>>d.pop('Bob‘)
80
>>>d
{'Mike': 95, 'Alice': 85}>>>s = set([1, 2, 3])
>>>s
{1, 2, 3}>>>s.add(4)
>>>s
{1, 2, 3, 4}
>>>s.add(4)
>>>s
{1, 2, 3, 4}>>>s.remove(4)
>>>s
{1, 2, 3}>>>s1 = set([1, 2, 3])
>>>s2 = set([2, 3, 4])
>>>s1 & s2
{2, 3}
>>>s1 | s2
{1, 2, 3, 4}>>>a = ['c','b','a']
>>>a.srot()
>>>a
['a','b','c']>>>a = 'abc'
>>>a.replace('a','A')#我们将a替换成A
'ABC'
>>>a
'abc'#what?居然没变?>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc' 今天的学习就到这里,大家再见!
今天的学习就到这里,大家再见!a= input("weight:")
b= input("height:")
weight=float(a)
height=float(b)
bmi= weight/height**2
if bmi<18.5:
print("过轻")
elif 18.5<=bmi>=25:
print("正常")
elif 25<bmi>28:
print("过重")
elif 28<=bmi>=32:
print("肥胖")
else :
print("严重肥胖")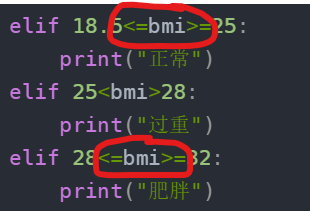 我的比较符号写错了,竟然两边都是≥号,估计我小学数学老师看见得揍死我。
新的知识
接下来,开始学习循环语句
python的循环有两种
我的比较符号写错了,竟然两边都是≥号,估计我小学数学老师看见得揍死我。
新的知识
接下来,开始学习循环语句
python的循环有两种for...in...whilefor...in...names = ["小红","小明","李华"]
for name in names:
print(name)
小红
小明
李华for x in ...whilesum=0
n=10
while n>0:
sum=sum+n
n=n-2
print(sum)30sumbreaksum=0
n=10
while n>0:
sum=sum+n
if sum>10:
break
n=n-2
print(sum)18breakn = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续进行下一轮循环,后面的print()语句不会执行
print(n)1
3
5
7
9continue






