

37,738
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享import requests
from bs4 import BeautifulSoup
url='https://music.163.com/#/discover/toplist' #云音乐飙升榜
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
res=requests.get(url=url,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
songs=soup.select('.m-table.m-table-rank tr')
for each in songs[2:3]: # 第一行表示标题
link='https://music.163.com/' + each.select('.txt a')[0]['href']
name=each.select('.txt a b')[0]['title']
# time=each.select('.u-dur')[0].text
pic=each.select('.tt .rpic')[0]['src']
# print('歌名:%s,地址:%s,图片:%s'%(name,link,pic))
print(link)

def save_song(name,url):
try:
print('正在下载:',name)
print(url)
urllib.request.urlretrieve(url,r'./songs/%s.mp3'% name)
print('下载成功')
except:
print('下载失败')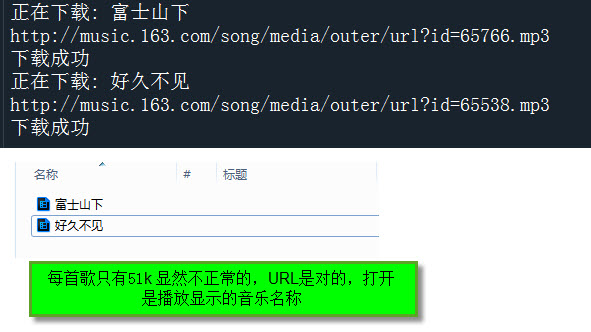 代码没有报错,且文件夹中也有下载的歌曲 就是歌曲的大小不对 无法播放 请教各位大侠这是什么情况?
代码没有报错,且文件夹中也有下载的歌曲 就是歌曲的大小不对 无法播放 请教各位大侠这是什么情况?song_list={}
songs=soup.select('#hotsong-list a')
for each in songs:
# link='https://music.163.com/' + each['href']
musicUrl='http://music.163.com/song/media/outer/url'+each['href'][5:]+'.mp3'
title=each.text
# print('歌名:%s,地址:%s'%(title,link))
song_list[title]=musicUrl

