


37,744
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.pearvideo.com/videoStatus.jsp?contId=1703247&mrd=0.9431604561367266'
data = requests.get(url=url, headers=headers).json()
print(data)
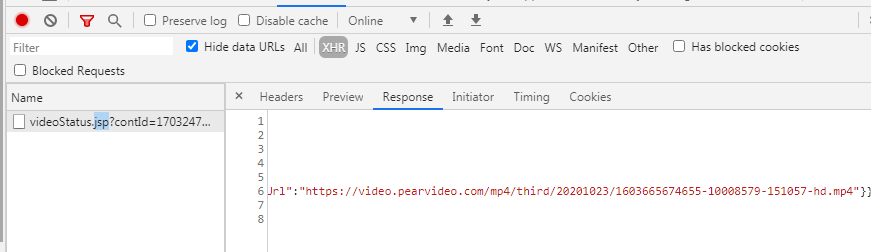


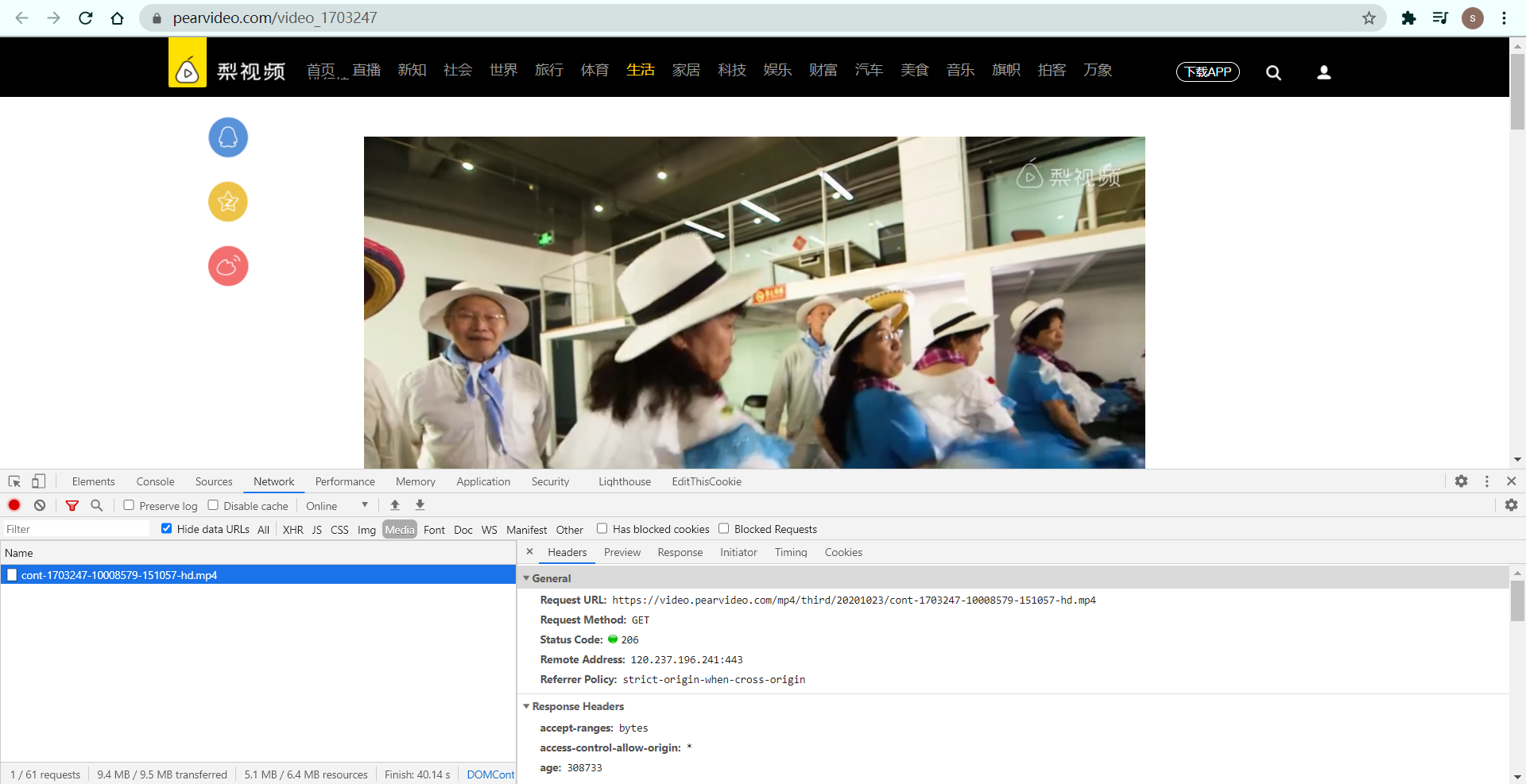 选择 Media那里,这个对应视音频文件。上图中显示的就是视频的链接。
还有,推荐以下两个爬虫教程,
【Python爬虫】Python爬虫入门,看这个就够了!!!
Python + Selenium爬虫,手把手教学从环境配置到项目实战!!
选择 Media那里,这个对应视音频文件。上图中显示的就是视频的链接。
还有,推荐以下两个爬虫教程,
【Python爬虫】Python爬虫入门,看这个就够了!!!
Python + Selenium爬虫,手把手教学从环境配置到项目实战!!

