社区
CUDA高性能计算讨论
帖子详情
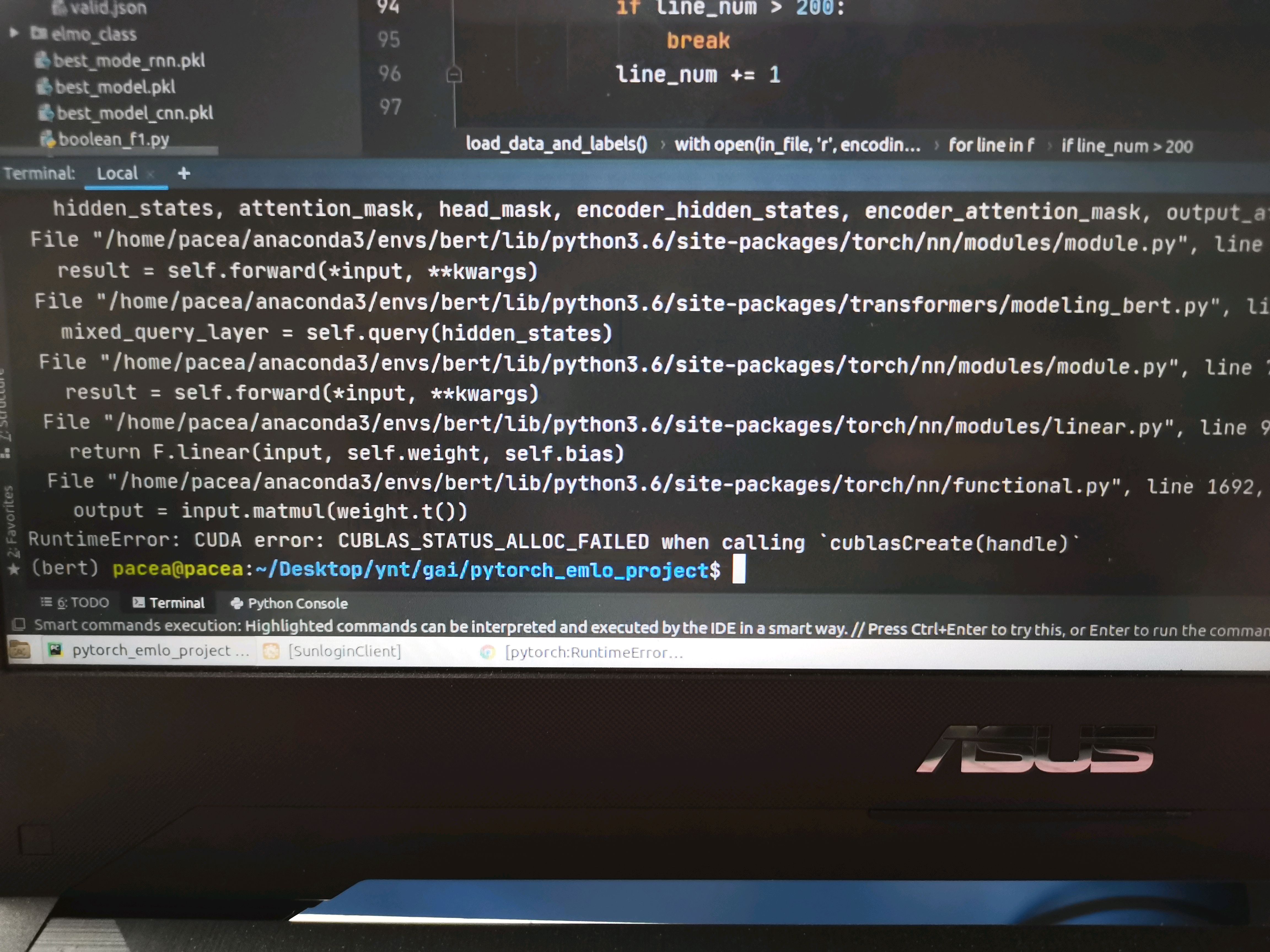
以pytorch为框架运行bert,在gpu内存分配遇到问题?在网上找解决方案,说是减小bachsize,减小后还是报错。
Emma_YeNT
2020-11-12 09:11:03
...全文
861
回复
打赏
收藏
以pytorch为框架运行bert,在gpu内存分配遇到问题?在网上找解决方案,说是减小bachsize,减小后还是报错。
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
dataloader合理设置num_works和batch
size
避免爆内存
本文探讨了如何合理设置
PyTorch
DataLoader中的num_workers和batch_
size
参数,以平衡内存和显存的使用,确保训练过程高效稳定
运行
。介绍了这些参数对CPU和
GPU
的影响,并给出了最佳实践建议。
RNN与torch DataParallel的爱恨情仇
本文探讨了在使用
PyTorch
的DataParallel进行多
GPU
加速RNN模型时
遇到
的
问题
,主要涉及RNN的state向量在不同维度的处理,以及如何协调DataParallel的切分规则。作者指出,由于RNN层期望batch
size
在第二个维度,而DataParallel默认按第一维度切分,这可能导致错误。
解决方案
包括在state送入模型前将其batch
size
调整到第一个维度,计算前后进行维度转换,并在模型输出后恢复维度,以确保正确计算损失。
丹青幻境·Z-Image Atelier详细步骤:4090显卡24GB内存下的最优batch
size
设置
YOLOv9官方Docker镜像解决了环境配置难题,实现开箱即用的训练与推理体验。通过预置兼容的
PyTorch
、CUDA及依赖库,统一代码路径与权重管理,用户可在3分钟内启动训练任务。镜像还支持内存映射、梯度检查点等优化技术,显著提升训练效率,降低显存消耗,适用于各类目标检测场景。
BGE-M3性能优化:让文本检索速度提升3倍
本文围绕BGE-M3在实际部署中推理延迟高的
问题
,提出三步可复用的性能优化方案:预热加载与显存锁定、Tokenizer流水线优化、
PyTorch
推理加速引擎注入。实测端到端耗时降低3.1倍,QPS提升3.2倍,显存占用减少37%,且未损失检索精度。同时涵盖Dense/Sparse/Col
BERT
三模态选型策略及生产级稳定性加固措施。
实用代码脚本易语言源码寻
找
磁盘文件
实用代码脚本易语言源码寻
找
磁盘文件
CUDA高性能计算讨论
357
社区成员
615
社区内容
发帖
与我相关
我的任务
CUDA高性能计算讨论
CUDA高性能计算讨论
复制链接
扫一扫
分享
社区描述
CUDA高性能计算讨论
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享