

37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import os
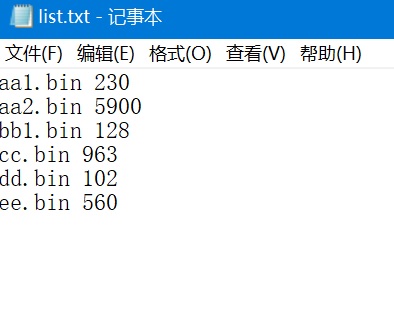
with open(path + 'list.txt') as f:
con = f.read().split("\n")
s = 0
size = os.path.getsize(path + 'xxx.bin')
with open(path + 'xxx.bin', 'rb') as f1:
for cc in con:
i, j = cc.split(' ')
j = int(j)
s += j
if j == -1:
j = size - s
with open(path + i, 'wb') as f2:
f2.write(f1.read(j))
import os
l = {'aa1.bin': 6, 'aa2.bin': 20, 'bb1.bin': 29, 'cc.bin': -1}
s = 0
size = os.path.getsize('xxx.bin')
with open(path+'\xxx.bin', 'rb') as f1:
for i, j in l.items():
s += j
if j == -1:
j = size - s
with open(path+'\\'+ i, 'wb') as f2:
f2.write(f1.read(j))
files = [('aa1.bin', 230), ('aa2.bin', 5900), ('bb1.bin', 128), ('cc.bin', 936)]
with open('xxx.bin') as binfile:
contents = binfile.read()
file_bytes = sum([file[1] for file in files])
assert (file_bytes <= len(contents))
start = 0
for afile in files:
end = start + afile[1]
content = contents[start:end]
start = end
with open(afile[0], 'w') as newfile:
newfile.write(content)
