社区
脚本语言
帖子详情
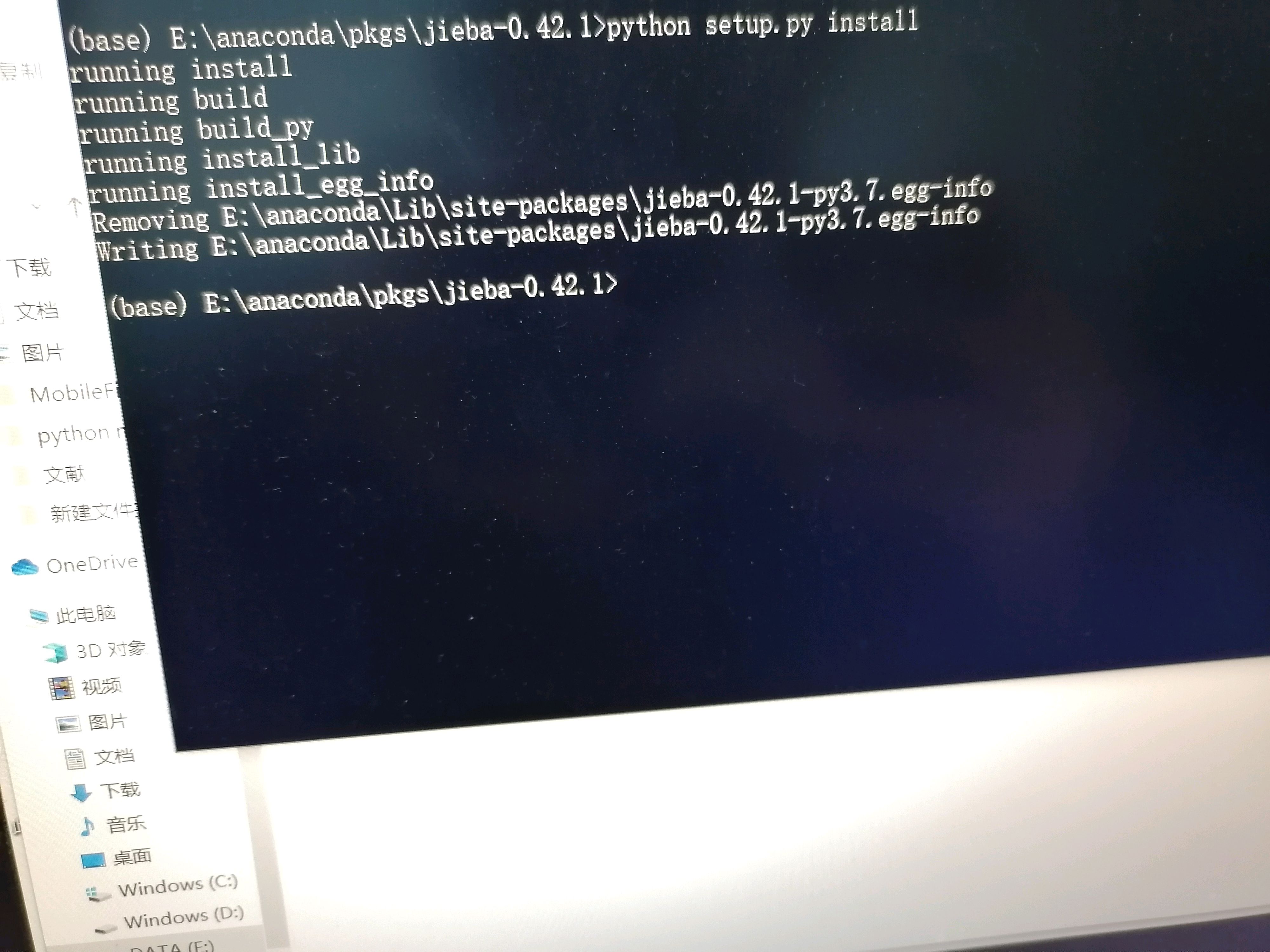
在acc中显示jieba已经安装,但是打开acc后发现找不到jieba.
qq_41950777
2020-12-02 10:46:36
...全文
99
回复
打赏
收藏
在acc中显示jieba已经安装,但是打开acc后发现找不到jieba.
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
NLU 语义解析评测实践:基于函数调用的
ACC
、ROUGE 与 BLEU 综合指标
在自然语言理解(NLU)语义解析场景
中
,传统分类准确率无法有效评估复杂结构化预测,需综合指标。本文介绍了意图准确率、整体解析准确率、ROUGE、BLEU等评测指标体系,给出实现方案、示例输出及计算
acc
的代码,包括贴合业务和通用NLP任务两种计算方式。
Python NLP实战手册:文本清洗+轻量模型+可部署API
本文聚焦工业级Python NLP落地实践,涵盖文本清洗(spaCy预处理、全角半角统一)、特征工程(TF-IDF+n-gram调优)、轻量模型选型(scikit-learn分类器、TextBlob极性分析)及Flask API封装全流程。强调模块化分层架构(清洗→特征→模型→应用),规避过拟合与数据泄露,并提供电商评论情感分析完整复现案例与常见幽灵Bug排查方案。
05阶段:NLP自然语言处理基础(1)
本文系统讲解NLP自然语言处理核心基础,涵盖文本预处理(分词、词性标注、命名实体识别)、文本张量表示方法(one-hot、word2vec、word embedding)、文本数据分析(长度分布、词频统计、词云),以及RNN及其变体(传统RNN、LSTM、GRU)的结构原理与PyTorch实现,并深入解析注意力机制在seq2seq英译法任务
中
的应用,包括编码器-解码器架构、teacher-forcing训练策略及Attention可视化分析。
DAGsHub:面向机器学习项目的可复现协作操作系统
DAGsHub是专为机器学习项目设计的可复现协作操作系统,深度融合DVC(数据版本控制)与Git,原生集成MLflow实验追踪。它解决ML工作流
中
数据-代码-模型-实验结果强耦合带来的复现性、协作熵增和审计难题,支持声明式数据版本化、自动血缘关联、Web UI可视化对比、CI/CD集成及合规报告生成,显著降低MLOps基础设施维护成本。
NLP对抗鲁棒性:从攻击防御到可验证认证的工程实践
本文系统阐述NLP模型对抗鲁棒性的工程落地路径,涵盖对抗攻击(如TextFooler、BAE)、对抗训练(FGSM/PGD、TRADES损失)与鲁棒性认证(随机平滑、IBP)三大核心技术;详解可复现的端到端流水线构建,包括工具链选型(PyTorch 2.0+、TextAttack 0.4.x)、
中
文数据预处理规范、轻量级在线对抗训练及三级评估体系;强调工业级实践要点:扰动控制、梯度裁剪、标点归一化、鲁棒性守门员架构与商业鲁棒性指数(BRI)。
脚本语言
37,739
社区成员
34,211
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
