社区
Web 开发
帖子详情
谁有中文识别率高的训练包??
javabugsmaker
2020-12-18 09:47:12
目前用的是tess4j,网上下的chi_sim.traineddata有50MB左右,识别率非常低,想自己训练又没时间,公司也安排不出人手。有没有识别率高的,90%左右就行,可以申请让公司出钱买。
不考虑百度、阿里、腾讯的在线识别服务,因为客户的服务器不允许连接外网,跟企业审计相关的涉密服务器没办法。
...全文
3809
4
打赏
收藏
谁有中文识别率高的训练包??
目前用的是tess4j,网上下的chi_sim.traineddata有50MB左右,识别率非常低,想自己训练又没时间,公司也安排不出人手。有没有识别率高的,90%左右就行,可以申请让公司出钱买。 不考虑百度、阿里、腾讯的在线识别服务,因为客户的服务器不允许连接外网,跟企业审计相关的涉密服务器没办法。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
KeepSayingNo
2020-12-19
打赏
举报
回复
不用翻墙啊,就是github的,我都登录进去了
qybao
2020-12-18
打赏
举报
回复
这个还真不好弄,LZ有时间还是自己训练试试吧,挺折腾的
首先字体图片不好到手,其次要训练哪种字体也不好范围确定(比如需要宋体,楷体等),第三,训练文件好像对字体的最大类型有限值(我记得当时做的时候,超过60种字体就不支持(猜测是训练字体太多最后生成的字体文件size太大,所以做了限制,或许可以考虑按60种字体做成多个字体文件后再合并,当时没时间去深究了),所以说你需要什么字体你要定好),但是你要求的90%识别率,由于前面的限制条件,那就不好说了,比如识别的字体没有出现在你训练的字体里,有可能识别率为0。
javabugsmaker
2020-12-18
打赏
举报
回复
引用 2 楼 KeepSayingNo 的回复:
用这个试试呢
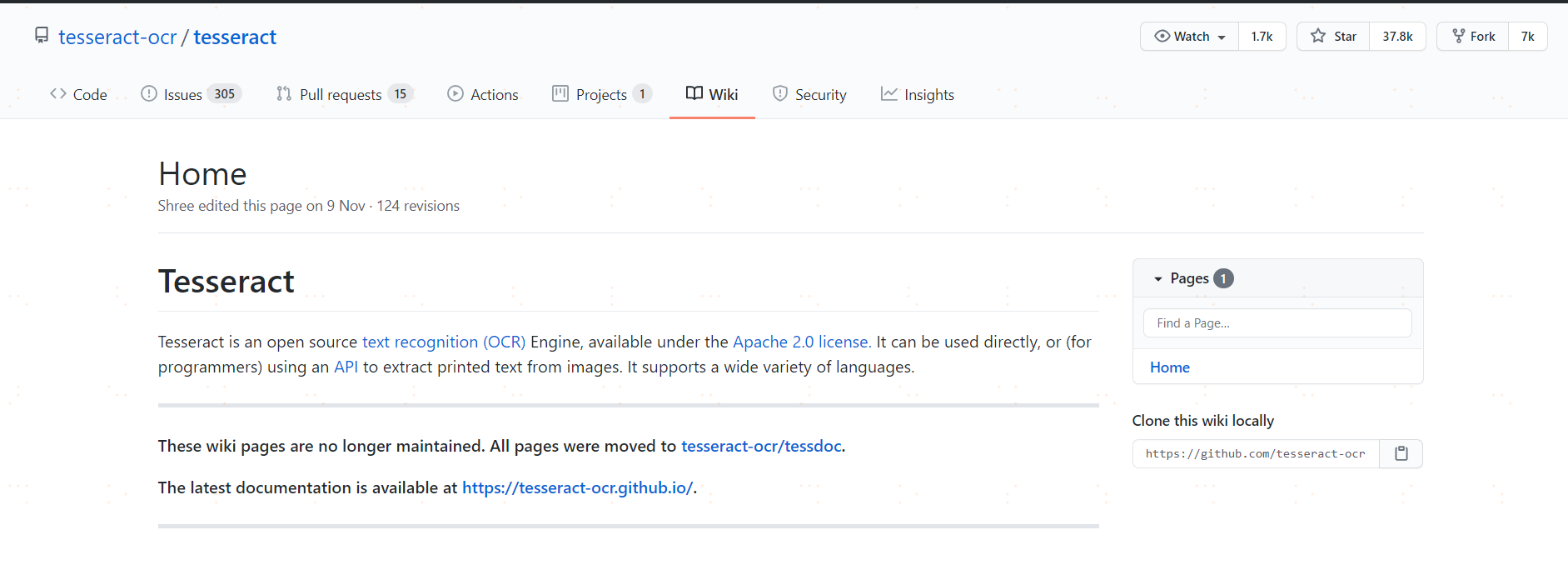
https://github.com/tesseract-ocr/tesseract/wiki
这个要翻墙吗,访问不得呢
KeepSayingNo
2020-12-18
打赏
举报
回复
用这个试试呢
https://github.com/tesseract-ocr/tesseract/wiki
HyperLPR:基于深度学习的
高
级
中文
车牌识别
高
性能
中文
车牌识别框架
HyperLPR
高
性能开源
中文
车牌识别框架 一键安装 python -m pip install hyperlpr 支持python3,支持Windows Mac Linux树莓派等。 实时720p cpu(在MBP r15 2.2GHz上具有stwell)。 快速上手 #导入
包
from hyperlpr import * #导入OpenCV库 import cv2 #读入图片 image = cv2 . imread ( "demo.jpg" ) #识别结果 print ( HyperLPR_plate_recognition ( image )) 问答环节 问:Android
识别率
没有所传demo apk的
识别率
高
? A:请使用下的模型,android默认
包
里的配置是相对较早的模型 问:车牌的
训练
数据来源? A:由于相关
训练
车牌数据涉及到法律隐私等问题,本项目无法提供。开放大的数据集有车牌数据集。 问:
训练
代码的提供? A:相关资源中有提供
训练
代码 问:关于项目的来源? 答:此项目预算作者早期的研究和调试代码,代码必须一定的规范,同时也欢迎PR。 相关资源 (感谢群内
Java OCR 图像智能字符识别技术,可识别
中文
Java OCR 图像智能字符识别技术,可识别
中文
。具体详见:http://blog.csdn.net/white__cat/article/details/38461449
Tesseract最新
中文
语言
包
chi-sim.traineddata
chi_sim.traineddata
tesseract-ocr安装
包
和
中文
语言
包
tesseract-ocr安装
包
和
中文
语言
包
,Python实现图片识别,python3识别图片里的文字,python3识别图片里的文字
简单验证码识别程序(只是程序,无源码)
对一些简单的验证码进行识别 实现语言:C#
Web 开发
81,116
社区成员
341,729
社区内容
发帖
与我相关
我的任务
Web 开发
Java Web 开发
复制链接
扫一扫
分享
社区描述
Java Web 开发
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享