社区
脚本语言
帖子详情
怎么用Python爬虫批量获取懂球帝球员数据啊 大佬们
BUPT丶云卷云舒
2021-01-17 09:40:05
我想把球员的姓名年龄各种数据抓下来做图
可是没有思路 哭了
...全文
1878
7
打赏
收藏
怎么用Python爬虫批量获取懂球帝球员数据啊 大佬们
我想把球员的姓名年龄各种数据抓下来做图 可是没有思路 哭了
复制链接
扫一扫
分享
转发到动态
举报
AI
作业
写回复
配置赞助广告
用AI写文章
7 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
lyn_CS
2021-02-02
打赏
举报
回复
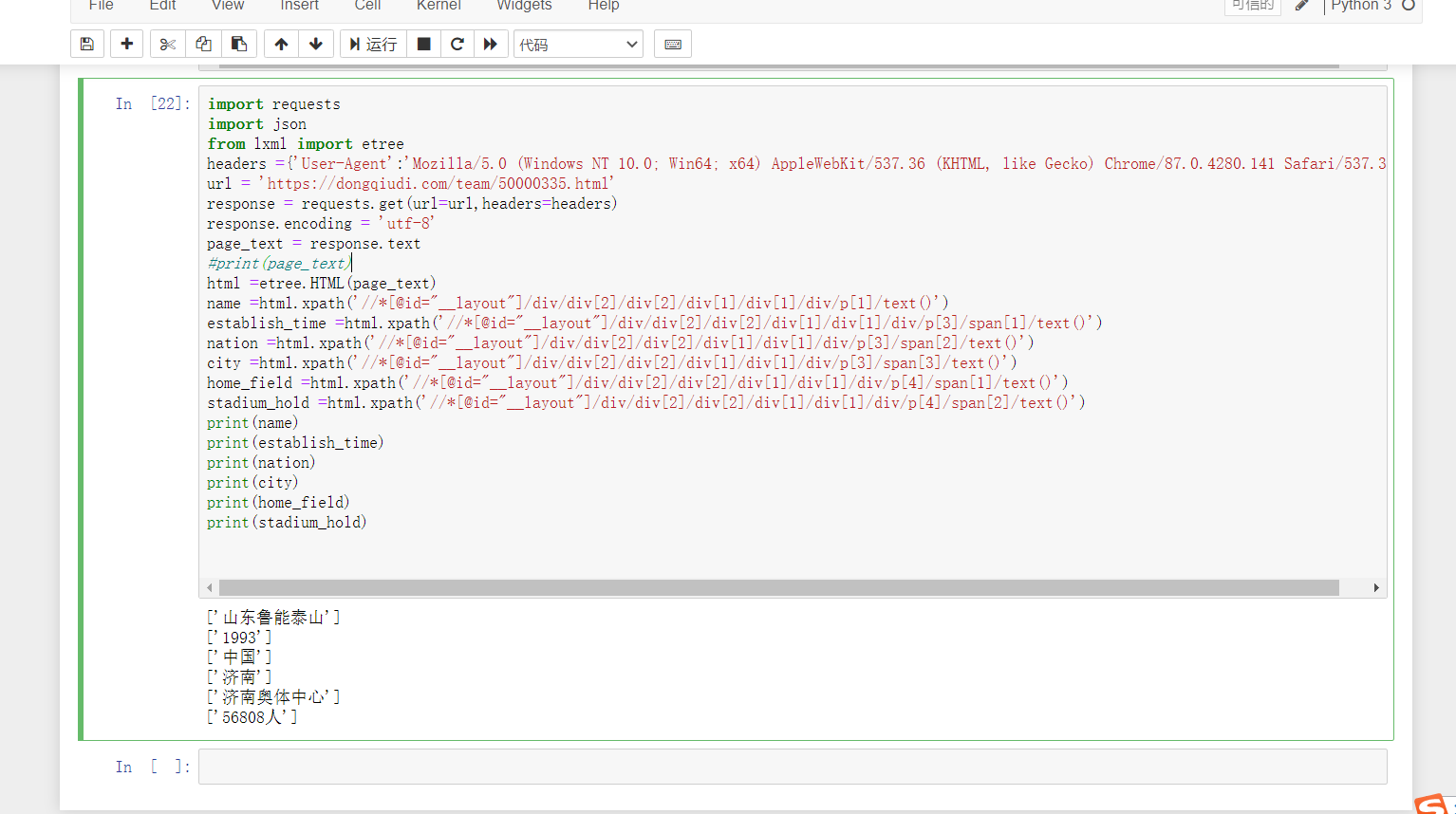
你再仔细看看,我告诉你过程了。你先去数据里找联赛id,比如你点一下西甲,不就在主页上看到西甲的id了吗。西甲看到的就是所有的西甲球队,而且那个页面的url就是用来请求联赛的接口,带着的参数就是西甲对应的参数。这个时候你就去返回找到西甲所有球队的id,你要明白页面渲染出来了,返回里一般就有返回数据用来构造页面的,所有的球队数据就在返回里。你再点一下对应球队,不就进入到球员数据里了。球队的接口数据就是你点击不同球队的那个url,你通过这个接口加球队id不就请求到了球员的页面了吗,再去请求返回里找球员id,把球员id保存起来,你再点击一下球员的不就看到了球员的数据接口的url和带的参数了,那个参数就是球员id用来构造请求的。不知道我说明白了没有。你最终的目的是找到所有球员的id和用来请求球员数据的url,但是球员的id要通过联赛-球队-球员找到。通过这个步骤你也可以将球员按照联赛-球队-球员串联起来
BUPT丶云卷云舒
2021-02-02
打赏
举报
回复
目前还只能爬一个队。。。
BUPT丶云卷云舒
2021-02-02
打赏
举报
回复
譬如英超球队的参数代码是从50000513(阿森纳)到50000556(布莱顿),中间还缺少的不少降级的球队,我要爬多个球队主页的时候怎么设置循环呢?
BUPT丶云卷云舒
2021-02-02
打赏
举报
回复
你的具体意思我明白了,奈何不会写基础爬虫代码,去哪能找到类似的我改改呢?
BUPT丶云卷云舒
2021-01-29
打赏
举报
回复
谢谢大佬。现在懂球帝新闻界面我能抓下来,用xpath解析到新闻标题。但是球员数据还是不知道具体要怎么弄,我想把五大联赛所有球员数据都抓到。我再看看吧= =
lyn_CS
2021-01-21
打赏
举报
回复
刚刚看了下懂帝的页面,说一下大致过程。你先去数据的主页面,它的每个联赛的id对应的是数字,每个联赛的id你手工点击不同联赛就能看到。每个球队的id通过联赛数据接口主页面请求的返回,懂帝的数据都在第一个请求的返回里。然后用联赛id去请求联赛那个接口,联赛的主页面的返回里找到球队的id,再用球队的id去请求球队的接口,从请求主页面里返回里找到球员id然后,然后根据每个球员的id去请求数据,数据返回也在主页面里。过程就是手工记录对应联赛的id-请求获取球队id-请求获取球员id-拿到数据
lyn_CS
2021-01-20
打赏
举报
回复
兄弟啊,要什么思路,先看一下懂球帝有没有反爬,没有就直接请求,有的话不会破解就用虚拟浏览器selenium 看一下球员的接口数据是从哪个接口返回的,找到它的入参,一般球员这种大概率是传个类似球员id进去,然而可能你并不知道球员id是什么,那就手工多看几个id,去猜一下大致的规律,然后自己去生成,有数据就拿,没有就过。拿到数据再。可是你又觉得不会前端,找不到球员数据的element,那就用xpath,谷歌的插件会自动帮你生成元素路径,去匹配就可以了
51c大模型~合集132
团队从
数据
的每个查询 x 中抽取开头词 w,然后构造相应的 SFT
数据
对 (Q (w), x),此外,团队还构造了一些负样本来帮助模型识别没有在训练中出现过的开头词,即对于没有在 D_1 中出现过的开头词 w’, 团队构造一条相应的拒绝回复 R (w’),表明没有见过相应的训练
数据
,这类
数据
构成的
数据
对为 (Q (w’),R (w’))。该打分公式的主要思想是,模型拒绝回复的可能性越低,或者模型一直重复某个特定的输出,都表明该开头词更有可能是真实在训练
数据
中出现的开头词。
深度学习算法加速.pptx
深度学习算法加速.pptx
港美股量化交易自动化程序
可实现在一定策略条件下,实现自动发现信号,自动买入、卖出,规避风险,增厚利润
基于
数据
挖掘的CRM体系在电子商务中应用研究.docx
基于
数据
挖掘的CRM体系在电子商务中应用研究.docx
教育物联网的应用.pptx
教育物联网的应用.pptx
脚本语言
37,743
社区成员
34,212
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享