社区
Hadoop生态社区
帖子详情
关于flume抽取oracle的增量数据sink到kafka的数据重复问题
qq_41198356
2021-01-23 10:29:11
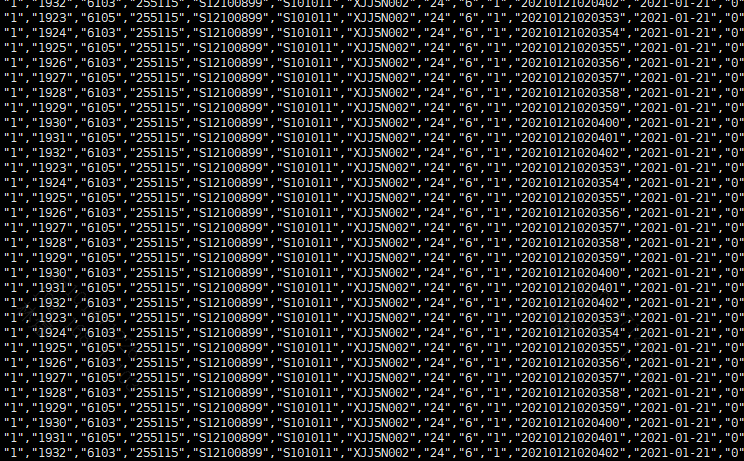
采用flume组件flume-ng-sql-source-1.5.2.jar连接上Oracle数据库后,通过配置flume抽取数据sink到kafka,kafka测试过没有问题了,但是运行flume的时候,kafka消费者中的数据就几万几万的跳,明明我的数据库里只有10条数据,全是重复数据,这种情况是flume的配置出问题了吗?
...全文
797
4
打赏
收藏
关于flume抽取oracle的增量数据sink到kafka的数据重复问题
采用flume组件flume-ng-sql-source-1.5.2.jar连接上Oracle数据库后,通过配置flume抽取数据sink到kafka,kafka测试过没有问题了,但是运行flume的时候,kafka消费者中的数据就几万几万的跳,明明我的数据库里只有10条数据,全是重复数据,这种情况是flume的配置出问题了吗?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
LinkSe7en
2021-03-31
打赏
举报
回复
你没有配置增量,当然每次都是全表采集辣 参考这个https://xhyangdali.github.io/2019/05/30/Flume%E5%A2%9E%E9%87%8F%E9%87%87%E9%9B%86Mysql%E6%95%B0%E6%8D%AE/
qq_41198356
2021-03-31
打赏
举报
回复
问题解决啦,加了个时间增量,但是现在不用这个,在研究kettle
qq_41162136
2021-03-23
打赏
举报
回复
这个问题你解决了吗兄弟
飞向海洋的猪
2021-02-18
打赏
举报
回复
为什么不用sqoop直接同步数据呢,我是第一次见到使用flume同步数据库中的数据,flume不是一般用来采集日志数据的吗?
大
数据
之
kafka
详解
Apache
Kafka
是一个开源消息系统,由Scala写成。...本教程从
kafka
概述开始,讲解了
kafka
的集群部署,详细的工作流程,java api操作,
kafka
的拦截器,以及
kafka
streams和
kafka
与
flume
的交互.让你快速上手
kafka
.
Flume
抽取
Oracle
中的
数据
到
Kafka
1.1
Flume
的安装 1)下载
Flume
从
Flume
官网(http://
flume
.apache.org/download.html)下载对应版本... 新建
flume
目录,将下载的
Flume
上传到该目录下,执行如下命令进行解压: tar -zxvf ./apache-
flume
-1.7....
flume
监控
Oracle
表变化
增量
抽取
数据
到
kafka
1.涉及到的软件框架及版本号 系统及软件 版本 CentOS centos7.2 JDK JDK1.8
Flume
flume
-1.9.0
kafka
kafka
_2.11-0.11.0.3 zookeper ...
Flume
1.8
抽取
Mysql或
Oracle
数据
转成JSON格式
Flume
1.8
抽取
Mysql或
Oracle
数据
转成JSON格式
Flume
增量
抽取
Oracle
数据
到
Kafka
在
Flume
的lib下引入如下两个包
flume
-ng-sql-source-1.5.2.jar ojdbc5.jar 配置flink文件 # declare source channel
sink
agentTest0.channels = channelTest0 agentTest0.sources = sourceTest0 agentTest0....
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享